
来源:https://zhuanlan.zhihu.com/p/2018378316042777476
摘要:本文证明,仅在仿真环境中训练的模型可用于解决真实机器人上复杂度前所未有的操作任务,这得益于两个核心组件:一种名为**自动域随机化(ADR)**的新型算法,以及为机器学习打造的机器人平台。自动域随机化能自动生成难度逐步提升的随机化环境分布,基于该算法训练的控制策略和视觉状态估计器,在仿真到现实的迁移性能上实现了大幅提升。对于控制策略而言,在自动域随机化生成的环境分布上训练的记忆增强型模型,在测试阶段呈现出明显的涌现式元学习特征。将自动域随机化与定制化机器人平台相结合,使我们能够利用仿人机械手完成魔方还原任务,该任务同时涉及控制和状态估计两大难题。
本文分为“上、下”两个部分:此为“上部分”,其中,第2节介绍研究中涉及的两项操作任务;第3节描述物理实验平台;第4节说明仿真环境中对该平台的建模方式;第5节提出新型算法——自动域随机化。
在后续发布的“下部分”中,将在第6、7节分别阐述控制策略和视觉状态估计器的训练方法;第8节展示两项任务的核心定量和定性实验结果;第9节系统性分析策略中涌现式元学习的特征;第10节综述相关研究;第11节为结论。
01简介
打造与人类具备同等通用性的机器人,仍是机器人领域的重大挑战。尽管仿人机器人系统已问世,但将其应用于现实世界的复杂任务,依旧困难重重。机器学习有望改变这一现状——通过学习利用传感器信息对机器人系统进行合理控制,而非依靠专家知识对机器人进行手工编程。
然而,机器学习需要海量的训练数据,而在物理系统上获取这些数据既困难又昂贵。因此,在仿真环境中收集所有训练数据成为一种极具吸引力的选择。但仿真无法在所有细节上精准还原真实的环境和机器人,这就要求我们解决由此产生的**仿真到现实(sim2real)**迁移问题。域随机化技术已展现出巨大潜力,证明了仅在仿真中训练的模型能够迁移至真实机器人系统。

在先前的研究中,我们实现了对单个方块的复杂手内操作。本次研究中,我们旨在仅利用仿真数据,通过Shadow灵巧手完成魔方还原所需的操作和状态估计任务。该任务的难度远高于此前的研究,因为还原魔方对操作的灵巧性和精准度有着极高要求,其状态估计问题也更为棘手——我们需要高精度获取魔方的位姿和内部状态信息。为实现这一目标,我们提出了一种新型方法,能自动生成随机化环境分布,用于训练强化学习策略和视觉状态估计器,我们将该算法命名为自动域随机化(ADR)。同时,我们搭建了一套机器人平台,以契合机器学习的方式在现实世界中完成魔方还原任务,系统整体架构如图2所示。
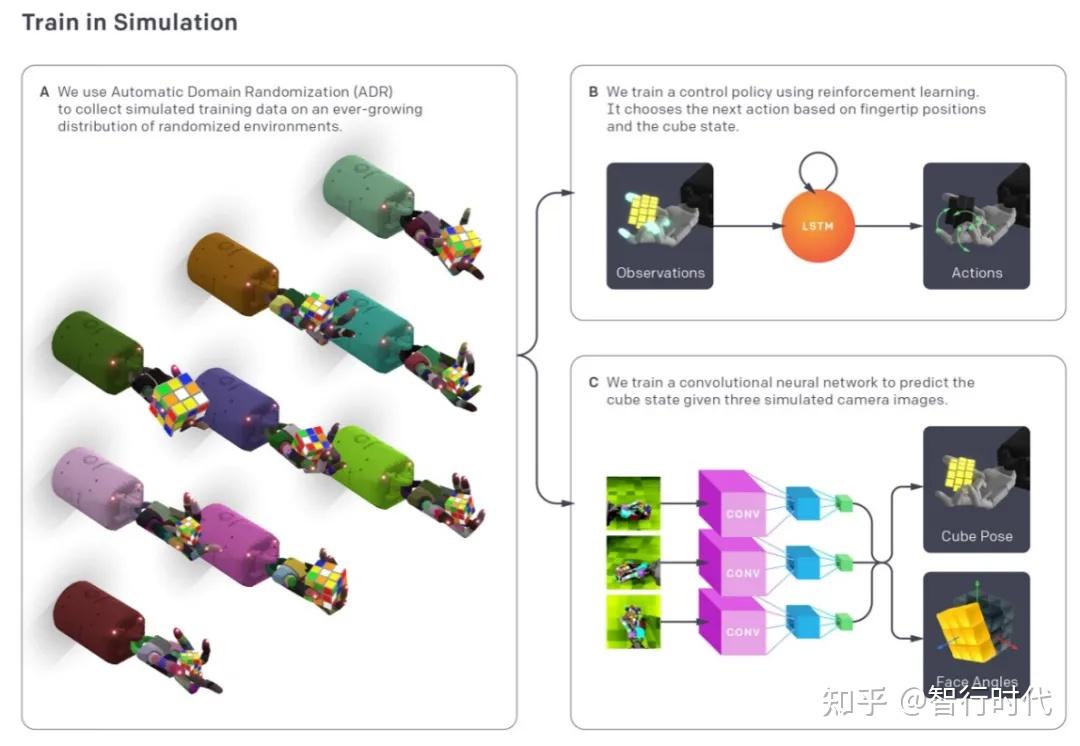
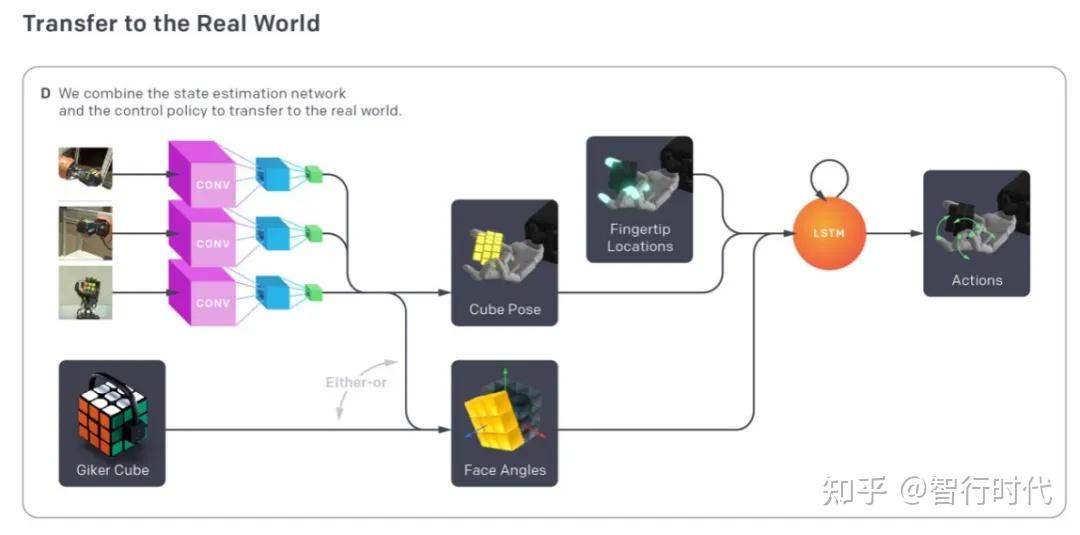
(a)利用自动域随机化生成参数和外观均随机化、难度逐步提升的仿真环境分布,该数据同时用于训练控制策略和视觉状态估计器;(b)控制策略接收随机化仿真环境中的机器人状态观测值和奖励信号,通过循环神经网络和强化学习学习完成任务的方法;(c)视觉状态估计器利用仿真中渲染的场景数据,通过卷积神经网络(CNN)预测魔方的位姿和各面旋转角度,该网络与控制策略独立训练;(d)在现实世界中,通过CNN从三台真实相机的拍摄画面中预测魔方位姿,利用3D运动捕捉系统测量机器人指尖位置;魔方内部旋转状态的各面角度信息,由上述视觉状态估计器或内置传感器的定制化Giiker魔方提供,最终将所有信息输入策略网络
我们探究了基于自动域随机化训练的策略为何能实现优异的仿真到现实迁移,发现在策略的循环内部状态中,测试阶段存在明显的涌现式学习特征。我们认为,这是在难度逐步提升的随机化环境分布上,采用记忆增强型策略进行训练的直接结果。换言之,在自动域随机化分布上训练长短期记忆网络(LSTM),本质上是一种隐式元学习。本文中,我们还对这一发现进行了系统性的研究和量化分析。
02任务
本研究中,我们利用Shadow灵巧手完成两项不同任务:此前研究中涉及的方块重定向任务,以及新增的魔方还原任务,两项任务的可视化结果如图3所示,本节将简要介绍各任务的细节。

2.1 方块重定向
方块重定向任务的提出,并实现了物理机器人手的实际操作,本节仅作简要回顾,更多细节可参考上述文献。
该任务的目标是将方块旋转至指定的目标姿态。例如,图3a中,目标姿态为方块红色面朝上、蓝色面朝左、绿色面朝向前方。当方块的实际旋转角度与目标角度的误差在0.4弧度以内时,判定为任务完成。完成一个目标后,将随机生成新的目标姿态。
2.2 魔方还原
本研究提出了一项难度显著更高的新任务:使用同一台Shadow灵巧手完成3×3魔方还原。简单来说,魔方是一个拥有6个内部自由度的益智玩具,由26个小立方体通过关节和弹簧系统连接而成。魔方的6个外表面均可旋转,从而实现打乱操作;当6个面均恢复为单一颜色时,判定为魔方还原完成。图3b展示了一个仅需将顶面旋转90°即可还原的魔方状态。
我们将魔方还原的子目标分为两类:旋转指将魔方单个面顺时针或逆时针旋转90°;翻转指将魔方的另一个面调整至顶面位置。研究发现,旋转顶面的难度远低于旋转其他面,因此我们不直接旋转任意面,而是将翻转和顶面旋转相结合完成指定操作。通过依次执行这些子目标,最终实现魔方还原。
魔方还原的难度显然取决于其初始打乱程度,我们采用世界魔方协会规定的官方打乱方法,生成“公平打乱”的魔方状态。一次公平打乱通常包含约20步操作,通过对还原状态的魔方执行这些操作实现打乱。
在魔方还原问题中,利用现有软件库(如Kociemba求解器)即可轻松计算出还原步骤序列。本研究中,我们使用该求解器生成机械手需要执行的子目标序列,因此核心问题并非寻找还原步骤,而是感知与控制:即获取魔方的状态(位姿和6个面的旋转角度),并利用该信息控制机械手精准完成每个子目标。
03物理实验平台
在介绍任务后,本节将描述在现实世界中完成方块重定向和魔方还原任务所使用的物理实验平台。由于已详细介绍方块重定向的物理平台,本节将重点阐述为实现魔方还原所做的改进。
3.1 机器人平台
本研究的机器人平台基于相关研究的配置搭建,仍使用Shadow灵巧手E系列(E3M5R)作为仿人机械手,通过PhaseSpace运动捕捉系统跟踪五指指尖的直角坐标,同时使用三台RGB巴斯勒相机完成视觉位姿估计。
但相较于此前的研究,我们进行了多项改进。图4a展示了最新版本的机器人实验舱,该实验舱为全封闭式设计,所有计算机均集成于系统内部;底部配备滚轮,便于移动;更大的舱体尺寸不仅让PhaseSpace运动捕捉系统的标定更简便,还能避免机械手进出舱体时对标定结果造成干扰。

我们对E3M5R灵巧手进行了多项定制化改装(见图4b):将连接指尖PhaseSpace LED与手部微驱动器的线路内置,减少线路的磨损;与Shadow机器人公司⁴合作,对实验中发现易损坏的部分组件进行优化,提升其鲁棒性和可靠性;改造手指末端结构,扩大橡胶覆盖面积,增强机械手与物体交互时的抓握力;增大腕部屈伸滑轮的直径,降低肌腱所受应力,使肌腱的平均无故障工作时间(MTBF)提升至原来的三倍以上;此外,对机械手的肌腱张紧器进行升级,使手指肌腱的平均无故障工作时间提升约5至10倍。
我们还对与E3M5R交互的软件栈进行了改进。例如,研究发现,手动调整每个电机的最大输出扭矩,在避免物理损坏和保证策略性能稳定性方面,效果优于自动调参方法。具体而言,我们将扭矩限制降至最小值,以确保机械手能稳定达到一系列指令指定的位置。
同时,我们搭建了实时系统监控模块,以便更快地发现并解决物理平台出现的问题。
3.2 Giiker智能魔方
仅通过视觉感知魔方的状态是一项极具挑战性的任务,因此我们采用内置传感器和蓝牙模块的“智能魔方”作为过渡方案:在视觉面角度预测模型尚未完成时,利用该魔方获取状态信息,继续开展控制策略的研究;同时,在部分实验中使用该魔方测试控制策略,避免视觉模型的面角度预测误差与策略误差叠加(位姿估计始终由视觉模型完成)。
本研究使用的硬件基于小米Giiker魔方,该魔方配备蓝牙模块,可实现状态感知,但其一阶面角度分辨率仅为90°,无法满足机器人平台的状态跟踪精度要求。因此,我们替换了原装Giiker魔方的部分组件,将跟踪精度提升至约5°。图5a展示了原装Giiker魔方的组件、定制化替换组件,以及组装后的定制版魔方。本文中后续提及的“Giiker魔方”均指该定制版本。

(i)底部中心外壳、(ii)锂聚合物电池、(iii)带蓝牙低功耗(BLE)模块的主印刷电路板(PCBa)、(iv)顶部中心外壳、(v)小立方体底部、(vi)压缩弹簧、(vii)接触电刷、(viii)绝对电阻式旋转编码器、(ix)锁定盖、(x)小立方体顶部;(b)组装完成的 Giiker 魔方充电状态
3.2.1 设计方案
除外部小立方体结构外,我们重新设计了Giiker魔方的所有内部部件。重新设计中心支撑结构,将分型线移出中心对称线,使其成为更易开发的平台——原装设计需要通过拆焊才能对微控制器进行编程。主蓝牙和信号处理板基于Nordic nRF52集成电路搭建;设计六块独立的印刷电路板(图6b),通过绝对电阻式编码器布局,将角度分辨率从90°提升至5°;利用图6a所示的线性化电路读取编码器位置,线性化后的模拟信号由微控制器的模数转换(ADC)引脚采集,并通过蓝牙低功耗(BLE)连接将面角度信息发送至主机。

定制化固件实现了基于Nordic UART服务(NUS)的通信协议,通过BLE模拟串行端口。我们开发了基于Node.js的客户端应用,定期向UART模块请求角度读数,并在需要时发送标定请求以重置角度参考值。从还原状态的魔方开始,客户端能够实时跟踪魔方的面旋转操作,通过周期性的角度读数重构魔方的状态。
3.2.2 数据精度与更新频率
为保证物理实验的可靠性,我们对组装后的Giiker魔方进行定期的精度跟踪测试。在精度评估中,将魔方每个面的四次直角旋转位置作为参考点,通过采集各参考点的测量值估计传感器精度。对两台定制魔方的测试结果显示,电阻式编码器的绝对平均跟踪误差为5.90°,参考点读数的标准差为7.61°。
实验中,我们将角度读数的更新频率设置为12.5Hz,该频率足以向机器人策略提供低延迟的状态观测值。
3.2.3 标定方法
我们通过固件和软件层面的联合标定,确保每个面角度传感器的零位可动态设置。首次连接魔方时,通过重置请求在固件中记录每个传感器的ADC偏移量;此外,在机器人每次物理实验开始前,通过软件重置角度读数,避免传感器误差在实验间累积。
为跟踪全定制硬件的传感器精度随时间的物理衰减,我们设计了一套标定流程:操作人员将魔方每个面完整旋转360°,并在每90°对齐位置停止,通过记录预期角度和实际测量角度,评估传感器的长期精度。
04仿真环境
本研究的仿真平台:采用MuJoCo物理引擎对物理系统进行仿真,基于Unity3D搭建的远程渲染后端ORRB,渲染合成图像用于训练视觉位姿估计器。
尽管仿真无法完美复刻现实,但精准建模物理实验平台仍有助于缩小仿真与现实的差距。因此,我们对Shadow灵巧手的MuJoCo模型进行了进一步改进,通过新的动力学标定和对物理手中部分肌腱的建模,使仿真模型更贴合物理系统;同时,我们构建了高精度的魔方仿真模型。
4.1 机械手动力学标定
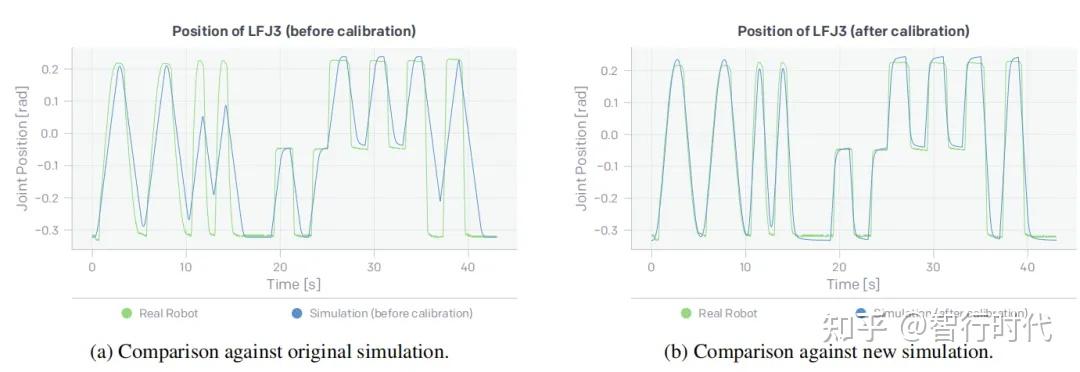
在机械手可自由运动的环境中,我们测量了真实机械手和仿真机械手在同一动作时间序列下的关节位置,得到两项发现:
1. 物理机器人和仿真环境中记录的关节位置存在明显差异(见图8a);
2. 耦合关节(即非拇指手指的末端两个关节)的动力学特性在物理机器人和仿真中存在差异。使用的原始仿真模型通过两根固定肌腱对耦合关节的运动进行建模,导致每个动作下两个关节的运动距离大致相同;但在物理机械手中,耦合关节的运动取决于每个关节的当前位置——与人类手部相似,手指弯曲时,近端节段先于远端节段弯曲。
为解决耦合关节的动力学建模问题,我们在仿真中的非拇指手指上添加了非驱动空间肌腱和滑轮(见图7),与物理机械手中的非驱动肌腱结构一致。随后,对标定新 MuJoCo 模型中与关节运动相关的参数,最小化同一动作时间序列下,物理机器人记录的参考关节位置与仿真中记录的关节位置之间的均方根误差。研究发现,优化后的耦合关节建模和动力学标定显著提升了仿真性能。

4.2 魔方建模
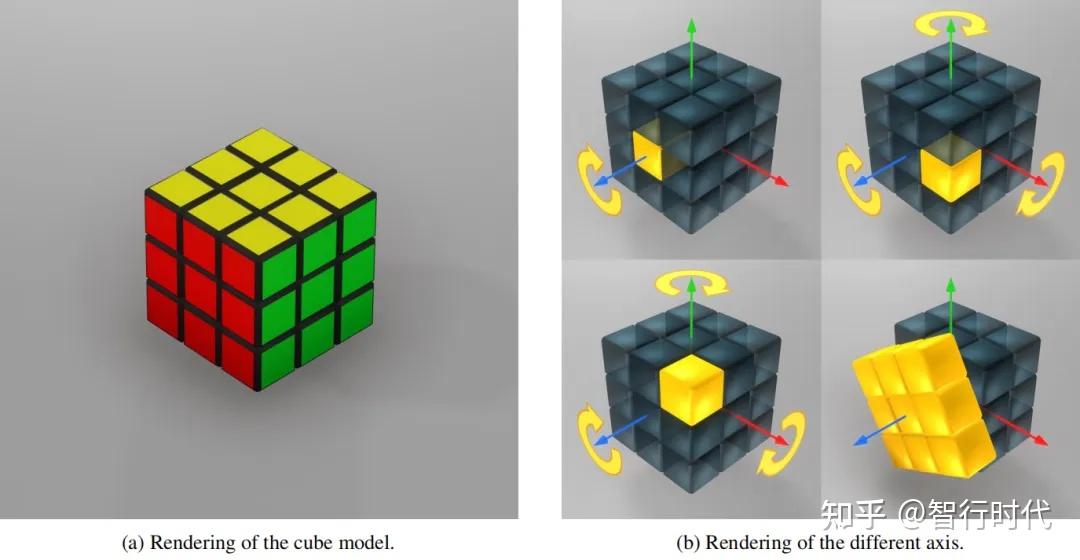
魔方看似是简单的立方体结构,但其内部具有高度的复杂性,各部件间的相互作用也并非简单的刚体接触。标准的3×3魔方由26个外露的小立方体组成,这些小立方体相互连接形成一个大立方体。六个面中心的小立方体通过轴与内部核心连接,仅能绕单一轴旋转,拥有一个自由度;而棱块和角块并非固定,当魔方的大面旋转时,这些小立方体可绕魔方整体移动。为防止魔方散架,每个小立方体都有延伸至核心的塑料凸舌,通过相邻部件的相互约束保持位置,最终由中心块固定整体结构。此外,大多数魔方都具有一定的弹性,允许产生微小的形变,这也带来了额外的自由度。
魔方的各组件之间持续存在相互作用力,导致系统内存在基础摩擦力——既包括小立方体之间的接触摩擦,也包括关节处的摩擦。对单个小立方体施加力即可实现整个面的旋转,因为该力会通过接触力在相邻部件间传递。尽管魔方有六个可旋转的面,但并非所有面都能同时旋转:当一个面已旋转一定角度后,与其垂直的面会处于锁定状态而无法旋转;但如果旋转角度足够小,已旋转的面通常会“回弹”至最近的对齐位置,此时即可旋转垂直的面。魔方的这一特性被称为“容错性”,不同市售型号的魔方容错性差异显著。
由于我们完全在仿真中训练模型,且需要在从未接触过真实魔方的情况下实现优异的仿真到现实迁移,因此需要构建一个足够精细的模型,包含上述所有特性,同时兼顾软件复杂度和计算成本。我们采用MuJoCo物理引擎,该引擎为具有软接触的刚体动力学提供了稳定、高效的数值求解方案。
受物理魔方的结构启发,我们的仿真模型由26个刚体凸面小立方体组成。MuJoCo允许这些形状在受力时产生微小的相互穿透。六个中心小立方体各有一个铰链关节,代表绕穿过魔方中心、与对应面垂直的轴旋转的单一自由度;其余20个角块和棱块各有三个铰链关节,对应欧拉角的完整表示,旋转轴均穿过魔方中心。由此,我们的魔方模型拥有6×1+20×3=66个自由度,不仅能有效表示魔方的43万亿种对齐状态,还能表示所有物理上有效的中间状态。
所有小立方体的网格模型均基于边长1.9cm的立方体构建。初步实验发现,完美的立方体形状会导致魔方仿真模型的容错性极差,因此我们将网格的所有边缘向内倒角1.425mm,得到了符合预期的容错性结果。我们未在建模中实现任何自定义物理规则,仅依靠小立方体的形状、接触力和摩擦力驱动魔方的运动。我们也曾尝试通过弹簧关节建模魔方形变带来的额外自由度,但发现MuJoCo原生的软接触已能表现出相似的动力学特性,因此未采用该方案。
我们对MuJoCo中可配置的参数进行了基础的动力学标定,使仿真模型大致匹配物理魔方的特性。研究目标并非实现完全精准的匹配,而是构建一个合理的模型,作为域随机化的起点。
05自动域随机化
我们通过域随机化在仿真中训练控制策略和视觉模型,并成功将两者迁移至真实机器人,但这一过程需要大量的人工调参,以及仿真域随机化设计与机器人实际验证之间的紧密迭代。本节将介绍**自动域随机化(ADR)**如何实现这一过程的自动化,以及如何将其应用于策略和视觉模型的训练。
自动域随机化的核心假设是:在最大化多样化的环境分布上训练模型,能够通过涌现式元学习实现优异的仿真到现实迁移。具体而言,如果模型具备记忆能力,就能在部署过程中调整自身行为,逐步提升在当前环境中的性能,即通过内部实现一种学习算法。我们认为,当训练分布的复杂度足够高,模型因容量有限无法为每个环境记忆专用的解决方案时,就会出现这种涌现式学习。自动域随机化是实现无界环境复杂度的第一步:它能自动生成并逐步扩展参数化环境分布的随机化范围。
本节将首先从宏观层面介绍自动域随机化的工作原理,随后详细阐述算法设计和实现方案。
5.1 自动域随机化概述
我们将自动域随机化同时应用于视觉模型(监督学习)和控制策略(强化学习)的训练。在两种场景中,均通过随机化环境的特定属性(如魔方的视觉外观、机械手的动力学特性等)生成环境分布。传统域随机化需要人工定义该分布的范围,并在模型训练过程中保持固定;而自动域随机化能自动定义分布范围,并允许其随训练过程动态调整。
图10为自动域随机化的顶层流程图,下文将对其进行直观概述,算法的形式化描述见5.2节。
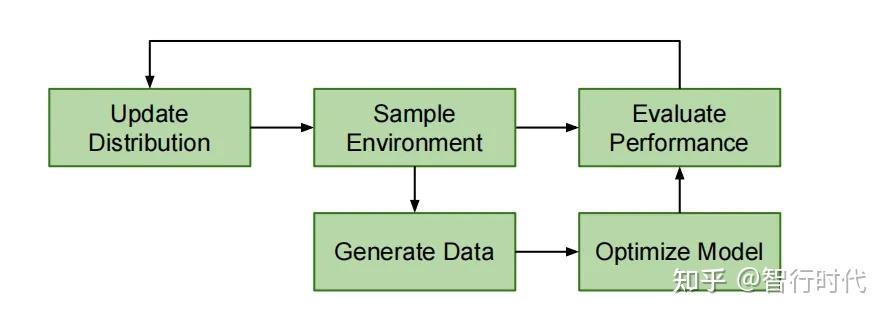
自动域随机化控制环境分布的生成,从该分布中采样环境并生成训练数据,用于优化模型(策略或视觉状态估计器);同时,评估模型在当前环境分布上的性能,并利用该性能信息自动更新环境分布
自动域随机化的核心是实现一种训练课程,逐步扩展模型能够良好执行任务的环境分布。初始的环境分布集中于单一环境,例如,策略训练的初始环境基于从物理机器人测量得到的标定值。
通过对环境分布进行采样,得到用于生成训练数据和评估模型性能的环境。自动域随机化与模型训练算法相互独立,仅负责生成训练数据,这使其可同时应用于策略和视觉模型的训练。
随着训练的推进,当模型在初始环境中的性能提升至预设水平后,环境分布的范围将被扩展;只要模型性能保持在可接受范围内,这种扩展就会持续进行。对于性能足够强大的模型架构和训练算法,环境分布的扩展范围有望远超人工域随机化的设定,因为模型性能的每一次提升都会触发随机化范围的扩大。与人工域随机化(DR)相比,自动域随机化具有两大核心优势:
1. 采用难度随训练逐步提升的课程训练策略,简化了训练过程——模型首先在单一环境中解决任务,仅当性能达到最低要求后,才会引入新的环境;
2. 无需人工调参随机化参数,这一点至关重要,因为随着随机化参数的增加,人工调整会变得愈发困难且缺乏直观性。
模型的“可接受性能”由性能阈值定义:对于策略训练,阈值为单轮实验中成功次数的上下限;对于视觉模型训练,首先为每个输出(如位置、姿态)配置目标性能阈值,评估时计算所有输出均达到目标阈值的样本占比,若该占比高于上限阈值或低于下限阈值,则相应调整环境分布。
5.2 算法设计
每个环境eλ由参数λ∈Rd表征,其中d为仿真中可随机化的参数数量。在传统域随机化(DR)中,环境参数λ来自由ϕ∈Rd′参数化的固定分布Pϕ;而在自动域随机化(ADR)中,ϕ会随训练进度动态变化。图 10 中的采样过程可表示为λ∼Pϕ,最终得到一个随机化环境实例eλ。
为量化自动域随机化的扩展程度,我们定义ADR熵为:

单位为每维度奈特(nats/dimension)。ADR熵越高,表明随机化采样分布的范围越广,归一化处理使我们能够对不同的环境参数化方式进行比较。
本研究中,采用由d′=2d个参数表征的因式分布。为简化符号,将ϕ划分为ϕL,ϕH∈Rd。对于第i个ADR参数λi(i=1,…,d),使用数对

描述λi的均匀采样分布,即
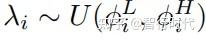
(边界值包含在内)。整体分布可表示为:
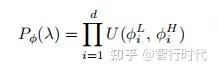
对应的ADR熵为:
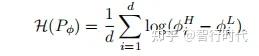
自动域随机化算法如算法1所示,对于因式分布,该算法将分别应用于ϕL和ϕH。
在每次迭代中,自动域随机化算法随机选择一个环境维度λi,将其固定为边界值

(我们称之为“边界采样”),其余参数则按照Pϕ进行采样;随后评估模型在该采样环境中的性能,并将结果添加至所选参数对应边界的性能缓冲区;当性能缓冲区收集到足够数据后,计算平均值并与阈值比较:若平均性能高于上限阈值tH,则增大该维度的参数值;若低于下限阈值tL,则减小该参数值。
如前所述,自动域随机化算法通过将单个环境参数固定为边界值来修改Pϕ。为生成模型训练数据,我们将算法2与自动域随机化结合使用:从Pϕ中采样λ,并在采样的环境中运行模型,生成训练数据。
为结合自动域随机化和训练数据生成,在每次迭代中,以概率pb执行算法 1,以概率1−pb执行算法2,我们将pb称为边界采样概率。


5.3 分布式实现
本研究中使用的是分布式版本的自动域随机化,策略和视觉模型训练的系统架构分别如图11a和11b所示。第6、7节将详细介绍策略和视觉模型的训练,本节重点阐述自动域随机化的分布式实现。
该高并行、异步的实现方案依赖于多个中心化存储模块,包括(策略或视觉)模型参数Θ、ADR参数Φ、训练数据T和性能数据缓冲区

我们采用Redis实现这些存储模块。
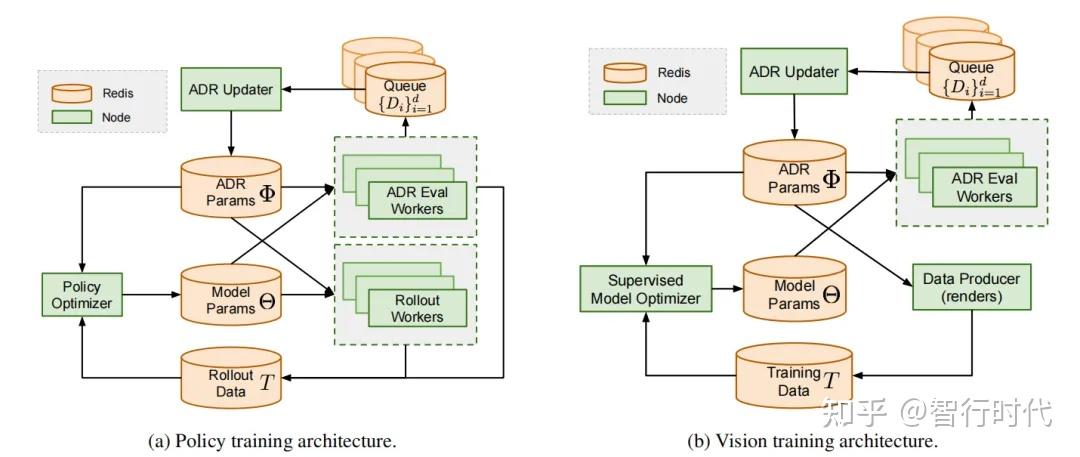
(左)策略训练;(右)视觉模型训练。两种场景均使用Redis中心化存储ADR参数(Φ)、模型参数(Θ)和训练数据(T);ADR评估工作线程运行算法1,通过边界采样估计模型性能,并将结果存入性能缓冲区({Di} d i=1)。ADR更新器利用这些缓冲区的平均性能,相应扩大或缩小随机化边界;策略训练的滚动工作线程和视觉模型训练的数据生成工作线程,根据当前ADR参数采样环境(见算法2)并生成数据,该数据随后由优化器用于提升策略和视觉模型的性能
通过中心化存储,自动域随机化算法与模型优化过程解耦。但要利用自动域随机化训练出高性能的策略或视觉模型,需要一个并发优化器,持续消费训练数据T并将更新后的模型参数推送至Θ。
我们采用W个并行工作线程替代串行的循环结构:对于策略训练,每个工作线程从Φ和Θ中获取最新的分布参数和模型参数,以概率pb执行算法1(图11a中标记为“ADR评估工作线程”),否则执行算法2并将生成的数据推送至T(标记为“滚动工作线程”)。为避免仅为ADR消耗大量数据,我们将这些数据同时用于策略训练。视觉模型训练的架构与之相似,不同之处在于:无需执行策略滚动,而是利用ADR参数渲染图像,用于训练监督式视觉状态估计器;由于视觉模型的训练数据生成成本更低,我们仅使用“数据生成工作线程”产生的数据进行训练,而不使用ADR评估工作线程的数据(见图11b)。
在策略模型中,初始ADR参数ϕ0基于标定的环境参数设置,对于所有i=1,…,d,满足

在视觉模型中,初始随机化参数设置为0,即

在算法开始时,将分布参数推送至Φ,供所有工作线程使用。
5.4 随机化类型
本节将介绍本研究中使用的随机化类别,绝大多数随机化针对标量环境参数λi,并由两个边界参数

在ADR中表征。部分随机化(如观测噪声)由多个环境参数控制,并由更多边界参数表征。
1. 仿真物理参数:随机化仿真的物理参数,如几何形状、摩擦力、重力等;
2. 自定义物理效应:建模仿真未涵盖的机器人物理效应,如动作延迟、电机间隙等,对这些模型的参数进行与仿真物理参数相似的随机化;
3. 对抗性扰动:采用相似的对抗方法,捕捉目标域中尚未建模的物理效应,不同之处在于我们使用随机网络而非训练后的对抗模型;
4. 观测噪声:为策略观测值添加高斯噪声,更好地模拟现实中的观测条件,包括相关噪声(在单轮实验开始时采样一次)和非相关噪声(在每个时间步采样一次),并对噪声参数进行随机化;
5. 视觉属性:在ORRB中随机化渲染场景的多个属性,包括光照条件、相机位置和角度、所有物体的材质和外观、背景纹理,以及渲染图像的后处理效果。
在该文的后续“下”部分中,我们将将分别阐述控制策略和视觉状态估计器的训练方法;展示两项任务的核心定量和定性实验结果;并系统性分析策略中涌现式元学习的特征。请持续关注“智行时代”公众号后续发布的该文章的“下”部分。
智行时代编者:AutoGo,智子 原文作者:Ilge Akkaya,Marcin Andrychowicz,Maciek Chociej,Mateusz Litwin,Bob McGrew,Arthur Petron,Alex Paino,Matthias Plappert,Glenn Powell,Raphael Ribas,Jonas Schneider,Nikolas Tezak,Jerry Tworek,Peter Welinder,Lilian Weng,Qiming Yuan,Wojciech Zaremba,Lei Zhang(免责声明:文中观点仅供分享交流,文章版权及解释权归原作者及发布单位所有)





评论0