
来源:https://zhuanlan.zhihu.com/p/694793688
一. 基本信息
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
该文是火爆的Aloha炒虾机器人的论文,介绍了如何使用模仿学习策略来使低成本的双臂机器人实现精细操作,文章发表在RSS 2023上,作者为Tony Z. Zhao,Vikash Kumar,Sergey Levine,Chelsea Finn,作者来自斯坦福,伯克利和Meta,值得一提的是,该文章中提到的aloha机器人的软硬件全部开源。

像是系扎带,给电视遥控器安装电池等细致的操作对于机器人而言还是较为困难的任务,因为这需要精确的接触力标定和完整的视觉反馈过程,所以完成这些任务往往需要搭载了精确传感器的,部署相对麻烦的,昂贵的高端机器人。那么能否使用学习的方法使得低成本的机器人也可以完成类似任务呢?作者提出了一套低成本软硬件解决方案:硬件上采用$20k的Aloha机器人与遥操纵系统,算法上使用作者改进过的模仿学习策略,以人类控制遥操纵系统完成实际任务的过程作为模仿学习的示例。
传统的模仿学习方法在解决一些问题,特别是高精度的问题的时候有着自己的弊端,像是预测策略序列的误差逐渐累积,人类的演示是不稳定的(应该指的是人可能有一些错误操纵)等等。为了解决这些问题,作者提出了Chunking with Transformers (ACT)方法,学习动作序列的生成模型。仅仅需要10分钟的演示,Aloha机器人可以学会6种像是打开半透明调料罐或者插入电池的精细操作,操作成功率在80%到90%之间。
作者拿打开一个调料罐的盖子举例子,实际操作过程如下:
杯子一开始直立地放置在桌子上,需要首先使用右夹具将其翻转,然后将其推入打开的左夹具中。然后左夹具轻轻闭合,将杯子从桌子上提起。接下来,右手的一根手指从下方接近杯子并撬开盖子。每一个步骤都需要高精度、细腻的手眼协调、丰富的接触力信息。毫米级的误差就会导致任务失败。但是,如果要实现这样毫米级精度的建模、规划、控制需要昂贵的高精度传感器。
但是人类同样没有这种毫米级的度量能力,却可以依据视觉反馈的闭环来不断调整自己手的位置从而实现打开盖子的结果,因此作者使用RGB图像作为反馈,端到端地输出下一步的动作,不断调整手的姿态,从而实现类似效果。

重新播放


为了有效地学习人类策略,作者搭建了一套低成本的遥操控系统(如下图所示),该系统配有两组低成本的机器人手臂。作者反驱一组小的机械臂,使用关节空间映射控制大的机械臂进行遥控操作。作者3D 打印了机器人的夹爪,从而在 $20k 美元的预算内打造出功能强大的遥操作系统。作者展示了使用该遥操纵系统丝滑地完成精确任务(例如穿扎带)、动态任务(例如杂耍乒乓球)以及接触丰富的任务(例如在 NIST 板上组装链条)等过程,视频可以参考项目网站。

为了解决模仿学习预测序列不断积累的组合误差(作者举了3个论文的例子来作证明),作者将接下来K步的预测结果组合为一个chunk进行预测。作者认为这将任务的序列长度缩短为原来的1/K,从而降低组合误差。同时,预测接下来K步也能解决一些与时间有关的混杂因素,像是描述示例过程中的停顿这样用单步马尔科夫决策不好描述的过程。
为了进一步提高策略的平滑性,作者还提出了时间集成的概念(temporal ensembling),频繁地计算action chunk 策略并且对重叠的部分取均值。作者采用Transformer结构(一种专为序列建模而设计的架构)实施action chunking策略,并将使用Conditional Variational Auto-Encoder(条件变分自编码器,CVAE)来进行训练。关于VAE和CVAE是什么可以参考下面这篇知乎的博客:
大黑:VAE v.s. CVAE 直观理解75 赞同 · 9 评论文章
二. Related Work
2.1 模仿学习策略(robot manipulation)
模仿学习允许机器人直接向专家学习。行为克隆(Behavioral Cloning)是最简单的模仿学习算法之一,将模仿视为从观察到行动的监督学习。之后的许多工作都试图改进Beahavioral Cloning,例如通过将历史信息与各种架构相结合,使用不同的训练目标,在框架中纳入regularization(Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration.)等等。其中,使用更多数据扩展模仿学习算法已经产生了令人印象深刻的改进,该方法可以泛化到新的对象、指令或场景。
在这项工作中,作者专注于构建一个低成本但能够执行精细操作任务的模仿学习系统。通过构建高性能遥操作系统和新颖的模仿学习算法,从硬件和软件两个方面解决成本问题,作者指出该算法极大地改进了以前fine manipulation的方法。
2.2 解决序列预测的组合误差问题
行为克隆(Behavioral Cloning)的一个主要缺点是组合误差,先前序列的错误逐渐累积并导致机器人偏离其训练分布,进入难以恢复的状态。这个问题在机器人精细操纵中尤为突出。减少组合误差的一种方法是允许额外的策略交互和专家修正,例如 DAgger方法和该方法的一些变体,DAgger方法可以参考下面这篇文章:
刘浚嘉:Imitation Learning Ⅱ: DAgger透彻理论分析78 赞同 · 11 评论文章
然而,使用遥操作界面进行expert annotation可能非常耗时且不自然。人们还可以在收集专家数据时注入噪声以获得具有纠正行为的数据集,但对于精细操作来说,这种噪声注入可能直接导致任务失败,降低遥操作系统的灵活性。为了规避这些问题,以前的工作以离线方式生成综合校正数据,但是它们仅限于低维状态可用的设置,或特定类型的任务(例如抓取)。由于这些限制,本文需要从一个不同的角度解决组合误差问题,与高维视觉观察兼容。我们建议通过动作分块来减少任务的有效范围,即预测动作序列而不是单个动作,然后跨重叠的动作块进行集成以产生既准确又平滑的轨迹。
2.3 双机械臂协作机器人
Bimanual manipulation在机器人技术领域有着悠久的历史,并且随着硬件成本的降低引发更多人的关注。早期工作往往从经典控制的角度,利用已知的环境动力学来解决双手操纵问题,但设计此类模型可能非常耗时,而且对于具有复杂物理属性的对象可能不准确。最近,基于学习的方法已被纳入双机械臂系统中,例如强化学习,模仿学习,或预测一些路径的keypoint或者是运动基元的组合。这里的“运动基元”(motor primitives)指的是机器人运动的基本单元或模式,它们可以被组合起来形成更复杂的动作序列。而“关键点”(key points)则是指在执行这些运动基元时,机器人需要特别关注或控制的特定位置、姿态或运动阶段。
有些工作专注于完成细致的操作任务,例如解开结、压平布料,甚至穿针,但这些工作往往使用价格昂贵得多的像是da Vinci或 ABB YuMi这样的机器人。作者期望使用低成本的机器人($ 5,000 per arm)执行高精度、闭环任务。作者设计使用的遥操作系统与 Heecheol Kim 等人之前的工作最相似,反驱一组机械臂,通过关节空间映射控制另外一组机械臂完成任务。但是与之前的系统不同,作者不使用特殊的编码器、传感器或机械部件而是仅使用在售的机械臂和少量 3D 打印零件构建系统,同时该系统可以在不到 2 小时的时间内快速完成组装。
三. Aloha:用于双手遥控操作的低成本开源硬件系统
作者寻求开发易于使用且高性能的机器人硬件,以进行精细操作,将设计考虑总结为以下5条准则。
(1) 低成本:整个系统应该在大多数机器人实验室的预算范围内,与单个工业机械臂价格相当。
(2) 多功能:可以应用于对现实世界物体的各种精细操作任务。
(3) 用户友好:系统应该直观、可靠、易于使用。
(4) 可修复:当装置不可避免地损坏时,研究人员可以轻松修复。
(5)易于构建:研究人员可以使用易于获取的材料快速组装。
在构建机器人的硬件时,作者依据原则1、4 和 5构建一个带有两个 ViperX 6-DoF 机械臂的双手平行爪夹具。出于价格和维护方面的考虑,该机器人不使用灵巧手,而采用作者自己设计的夹爪。
ViperX 6-DoF 机械臂的工作负载为750g,跨度为1.5m,精度为5-8mm,该机械臂采用模块化设计,易于维修。例如在电机出现故障的情况下,可以轻松更换低成本的 Dynamixel 电机,该机械臂价格约为 5600 美元,可以直接购买。然而,制造商原本提供的手指的通用性不足以处理精细的操作任务。因此,作者自己了3D 打印了如下图所示的手指,结构是有空洞的,可以see-through。这使得在执行精细操作时具有良好的可视性,并且即使在触碰薄塑料薄膜的情况下也能保持牢固的抓握力。

然后,作者寻求围绕 ViperX 机器人设计一个对用户友好的遥操作系统。作者有使用VR控制器或相机来捕获手部姿势并映射到机器人的末端执行器上(即任务空间映射),而是使用来自同一公司制造的较小机器人 WidowX 的直接进行关节空间映射,WidowX成本较低为3300 美元。用户通过反向驱动较小的 WidowX(“领导者”)进行远程操作,其关节与较大的 ViperX(“跟随者”)同步。在进行开发时,作者注意到与使用任务空间映射相比,使用关节空间映射的一些好处:
(1) 精细操纵通常需要在机器人的奇点附近进行操作,在作者的例子中具有 6 个自由度且无冗余。现成的反向运动学 (IK) 在此设置中经常求解失败。另一方面,关节空间映射保证了关节限制内的高带宽控制,同时还需要更少的计算并减少延迟时间。
(2) WidowX(“领导者”)机器人的重量可以防止用户移动得太快,同时也可以抑制微小的振动。作者注意到,与持有 VR 控制器相比,使用关节空间映射在精确任务上的性能更好。为了进一步改善远程操作体验,作者设计了一种3D打印的“手柄和剪刀”机构,可以改装到WidowX(“领导者”)机器人上(上图)。它减少了操作员反向驱动电机所需的力,并允许连续控制夹具,而不是只有打开或关闭动作。作者还设计了一个橡皮筋负载平衡机制,可以部分抵消引导侧的重力。该机制减少了操作员所需的工作量,并使更久的远程操作(例如 >30 分钟)成为可能。作者在项目网站中提供了有关设置的更多详细信息。
该装置的其余部分包括一个使用 铝型材的搭建的框架。共有四个 Logitech C922x 网络摄像头,每个摄像头传输 480×640 RGB 图像。其中两个网络摄像头安装在跟随机器人的手腕上,可以近距离观察夹具。其余两个摄像头分别安装在正面和顶部,遥控操作和数据记录均以 50Hz 进行。

考虑到上述设计考虑,作者在 2 万美元的预算内构建了双手遥控装置 ALOHA,大致相当于 Franka Emika Panda机器人的一个机械臂的价格。 ALOHA 可实现以下远程操作:
(1)精密任务,例如穿拉链扎带、从钱包中取出信用卡以及打开或关闭拉链袋。
(2)接触丰富的任务,例如将 288 针 RAM 插入计算机主板、翻书页以及在 NIST 板中组装链条和皮带
(3)动态任务,例如用乒乓球玩杂耍或者平衡球而不掉落,并在空中摆动打开塑料袋。
根据作者调研,预算5-10倍的遥操作系统也无法实现像是穿扎带、插入 RAM或玩乒乓球等技能。作者在附录中提供了更详细的价格和功能比较,以及 ALOHA 能够提供的更多技能。为了使 ALOHA 更易于使用,作者开源了所有软件和硬件,并提供了涵盖 3D 打印、组装的详细教程软件安装的框架,可以在项目网站上找到该教程。
四. 基于Transformer的预测动作序列Chunk的方法
作者认为现有的模仿学习算法在需要高频控制和视觉闭环反馈的精细任务上效果不佳。因此作者提出ACT方法,即Action Chunking with Transformers (ACT)。
为了训练 ACT 执行一项新的任务,作者需要首先使用Aloha机器人收集人类的演示过程。作者记录引导机器人的关节位置(即来自人类操作员的输入),将其作为动作序列(actions)。之所以使用领导机器人的关节位置而不是跟随机器人的关节位置,是因为跟随机器人所施加的力的大小是通过低级 PID 控制器计算它们之间的差值得到的,并不是直接定义,具有一定的滞后性。
网络的观测输入包含 跟随机器人的当前关节位置 和 4 个摄像机的图像。接下来,作者训练 ACT 并根据当前观测输入预测未来的动作序列( the sequence of future actions )。这里的动作(action)指的是下一时刻两个机械臂的关节期望位置。直观上,ACT 试图模仿人类操作员在给定当前观察结果的以下时间步骤中会做什么,然后使用PID 控制器对这些目标关节位置进行跟踪。在测试时,我们得到实现最低验证损失的策略,并在实际环境中应用该策略。出现的主要挑战是复合错误,先前操作的错误会导致机器人进入训练分布之外的状态。
4.1 动作分块(Action Chunking)和时间集成
为了在保证 “输入图像,输出动作序列” 策略不变的前提下,减小模仿学习的组合错误,作者寄希望于减少长程轨迹的有效范围。具体解释如下:作者受到动作分块这种神经科学概念的启发,一系列动作被分组在一起并作为一个单元执行,从而使它们更有效地存储和执行。直观上,一块动作可能对应于抓住糖果包装纸的一角或将电池插入插槽中。
在作者的实现中,将块大小固定为 � :每 � 步,网络接收一个观察结果,生成接下来的 � 个操作,并按顺序执行这些操作。这意味着任务的长度减少为原来的 1� 。具体来说,策略模型是 πθ(��:�+�|��) 而不是 πθ(��|��) 。分块还可以帮助建模人类演示过程中的非马尔可夫行为。具体来说,单步策略难以表示时间相关的混杂因素,例如演示中的暂停,因为行为不仅取决于状态,还取决于时间步长。动作分块可以当混杂因素在一个块内时解决这个问题,而不引入历史条件政策的因果混淆问题。
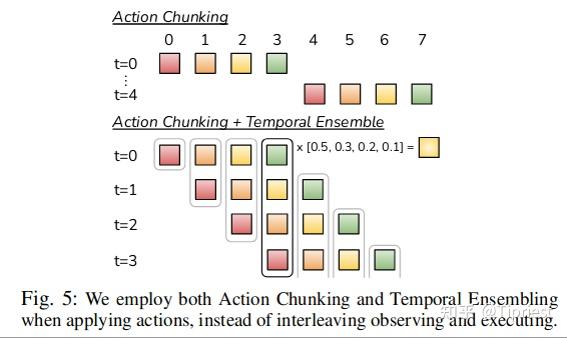
直接使用动作分块策略可能并不是一个最优策略,每 � 步之后观察一下环境并生成新的 � 步策略,这可能导致机器人运动衔接过程突变与不稳定。为了提高平滑度并避免两个块之间的离散切换过程,作者在每个时刻都计算接下来k步的action。这使得不同的动作块相互重叠,并且在某一时刻会有多个预测动作(来自之前 �−1 个时刻的预测结果)。作者在上图中对此进行了说明,并提出了一个时间集成的概念来组合这些预测结果。作者的时间集成概念使用指数加权方案 ��=�−�∗� 对历史预测进行加权平均,其中 �0 是最旧动作的权重。合并新观察的速度由 � 决定,其中 � 越小意味着合并速度越快。作者注意到,与典型的平滑过程不同,典型的平滑过程将不同时刻预测的动作进行融合,这会导致偏差,但是作者融合了不同时刻对同一时刻的预测动作,因此不会造成偏差,该过程也不会产生额外的训练成本,只会增加额外的推理时间计算消耗。在实践中,我们发现动作分块和时间集成对于 ACT 的成功非常重要,ACT 可以产生精确且平滑的运动,作者在第 六节的消融研究中更详细地讨论了这些组成部分。

4.2 Modeling human data
另一个挑战是如何从不稳定的人类演示过程中学习。在完全相同的场景前提输入下,人类接下来也可能使用不同的轨迹来完成任务。在精度不太重要的区域,人类的运动也往往会变得更加随机。因此,教会网络如何重点关注需要高精度的部分非常重要。作者通过将其提出的动作分块策略作为生成式模型进行训练来解决这个问题。具体来说,作者使用条件变分自动编码器(CVAE)来训练策略,根据当前观测输入,生成接下来的动作序列。 CVAE 由两个部分组成:CVAE 编码器和 CVAE 解码器,分别如下图的左侧和右侧所示。 CVAE 编码器仅用于训练 CVAE 解码器(策略),并在测试时被丢弃。
具体来说,CVAE 编码器预测风格变量 � 分布的均值和方差,以当前观察和动作序列作为输入,将 � 参数化为对角高斯分布。为了在实践中更快地进行训练,我们省略了图像观察,仅以本体感受观察和动作序列为条件。 CVAE 解码器,即策略,以 � 和当前观察(图像+关节位置)为条件来预测动作序列。在测试时,我们将 � 设置为先验分布的平均值,即零以进行确定性解码。整个模型经过训练以最大化演示过程动作块的对数似然函数,即 ���θ−∑��,��:�+�∈����πθ(��:�+�|��) ,标准 ��� 目标有两项:重建损失和将编码器正则化为高斯先验的项。按照一篇论文,我们用超参数 β 对第二项进行加权。直观上,较高的β将导致 � 中传输的信息较少[62]。总的来说,作者发现 CVAE 目标对于从人类演示过程中学习精确任务至关重要,作者在 VI-B 小节中进行了更详细的讨论。

4.3 实现 Action Trunking with transformers策略
作者使用 Transformer 实现 CVAE 编码器和解码器,因为 Transformer本身就被设计用于综合序列中的信息并生成新序列。 CVAE 的Encoder是用类似 BERT 的Transformer结构实现的。Encoder的输入是来自演示数据集的当前关节位置和长度为 � 的目标动作序列,在前面添加了类似于 BERT 的“[CLS]”token之后,就形成了 k+2维长度的输入(下图)。

经过 Transformer网络之后,使用“[CLS]”对应的特征来预测“风格变量” � 的均值和方差,然后将其作为decoder的输入。 CVAE decoder(即策略)将当前观测值和风格变量 � 作为输入,并预测接下来的 k 个动作。作者使用 ResNet 图像Encoder、一个基于Transformer的Encoder和一个基于Transformer的Decoder来实现 CVAE Decoder。直观地说,Transformer Encoder综合了来自不同相机视点、关节位置和风格变量的信息,Transformer Decoder生成连贯的动作序列。观察结果包括 4 张 RGB 图像,每张图像的分辨率为 480×640 ,以及两个机械臂的关节位置(总共 7+7=14 DoF)。动作空间是两个机器人的绝对关节位置,一个14维向量。因此,通过动作分块(Action Chunking),策略在给定当前观察的情况下输出 �×14 张量。
该策略首先使用 ResNet18 backbones 处理图像,将 480×640×3 ��� 图像转换为 15×20×512 特征图。然后作者沿着空间维度展平以获得 300×512 的序列。为了保留空间信息,作者添加一个 2D 正弦曲线位置嵌入到特征序列中[8]。对所有 4 个图像重复此操作,得到尺寸为 1200×512 的特征序列。然后作者附加两个特征:当前关节位置和“风格变量” � 。它们分别通过线性层从原始尺寸投影到512。因此,Transformer Encoder的输入维度是 1202×512 。
Transformer Decoder 通过交叉注意力对Encoder输出进行调节,其中输入序列是固定位置嵌入,尺寸为 �×512 ,keys和values来自Encoder。这为 Transformer Decoder提供了 �×512 的输出维度,然后使用 MLP 将其向下投影为 �×14 ,对应于接下来 � 个步骤的预测目标关节位置。作者使用 �1 损失而不是更常见的 �2 损失进行重建,因为作者注意到 �1 损失可以对动作序列进行更精确的建模。同时作者还注意到,当使用增量关节位置而不是目标关节位置作为动作时,性能会下降。作者在附录 C 中提供了详细的架构图。
作者总结了算法 1 和 2 中 ACT 的训练和推理过程。该模型有大约 80M 参数,对每个任务都从头开始训练。在单个 11G RTX 2080 Ti GPU 上训练大约需要 5 小时,在同一台机器上推理时间约为 0.01 秒。
五. 实验
作者通过实验来评估 ACT 在精细操作任务中的表现。为了便于重现,作者在 MuJoCo [63] 中建立了两个模拟精细操作任务,此外还利用 ALOHA 建立了 6 个真实世界的任务。同时作者在项目网站上提供了每个任务的视频。
5.1 任务
作者列举了使用Aloha机器人完成的 8 项任务,这8项任务都需要精细的双臂操作。在 “打开密封袋 “任务中,右侧抓手需要准确抓住密封袋的滑块并将其打开,而左侧抓手则负责固定袋身。

对于插入电池任务,右侧抓手需要先将电池放入遥控器的插槽中,然后用手指尖小心地推入电池边缘,直到电池完全插入。由于电池槽内的弹簧会导致遥控器在插入过程中向相反的方向移动,因此左抓手要向下按压遥控器,使其固定到位。

在 “开杯 “游戏中,目标是打开一个小调味品杯的盖子。由于杯子较小,抓手无法从侧面抓取杯身。因此,我们利用了两个抓手:右手手指首先轻轻敲击杯子边缘,将其翻转过来,然后将其推向打开的左手抓手。这个轻推步骤需要很高的精确度。然后,左手轻轻合拢,将杯子从桌子上拿起来,接着用右手指撬开杯盖,这也需要很高的精确度,以免错过杯盖或损坏杯子。

系上魔术贴的目标是将魔术贴扎线带的一端插入另一端连接的小环。左抓手需要先从桌上拿起魔术贴带子,然后右抓手在半空中捏住领带的尾部。然后,两只手臂协调配合,在半空中将魔术贴领带的一端插入另一端。根据位置的不同,环的尺寸为 3mm x 25mm,而魔术贴领带的尺寸为 2mm x 10-25mm。要成功完成这项任务,机器人必须利用视觉反馈来纠正每次抓取时出现的扰动,因为即使第一次抓取时出现几毫米的误差,在第二次抓取时也会在半空中加剧,导致插入阶段出现超过 10 毫米的偏差。

对于 “准备胶带“任务,目标是将一小段胶带挂在纸箱边缘。右抓手首先抓住胶带并用胶带分配器的刀片将其切断,然后在半空中将胶带段交给左抓手。接着,双臂靠近盒子,左臂将胶带段轻轻放在盒子表面,右手手指向下压胶带以防滑落,然后左臂打开抓手,松开胶带。与 “系上魔术贴 “类似,这项任务也需要两只手臂进行多步精细协调。

穿鞋的目标是将鞋穿在一个固定的人体模型脚上,并用鞋上的魔术贴带将其固定。双臂首先需要分别抓住鞋舌和鞋领,将其抬起并靠近脚。穿鞋是一项挑战,因为鞋子很紧:手臂需要小心协调,才能将脚伸进去,而且两只手都要抓得足够有力,才能抵消袜子和鞋子之间的摩擦力。然后,左臂绕到鞋底,支撑住鞋,防止其掉落,接着右臂翻转魔术贴带,将其压在鞋上固定。只有当两只手臂松开后鞋子紧紧贴在脚上,任务才算成功。

在Mujoco的模拟任务 “转移立方体 “中,右臂需要首先拿起桌面上的红色立方体,然后将其放入另一只手臂的夹钳中。由于立方体与左手抓手之间的间隙很小(约 1 厘米),微小的误差都可能导致碰撞和任务失败。

在模拟任务 “双臂插入 “中,左臂和右臂需要分别拿起插座和插销,然后在半空中插入,使插销接触到插座内的 “插针”。插入阶段的间隙约为 5 毫米。在所有 8 项任务中,物体的初始位置要么沿 15 厘米白色参考线随机变化(真实世界任务),要么在二维区域内均匀变化(模拟任务)。

除了解决这些任务所需的精细双臂控制外,我们所使用的物体也对感知能力提出了巨大挑战。例如,密封袋在很大程度上是透明的,只有一条细细的蓝色密封线。在随机化过程中,袋子上的褶皱和里面反光的包装纸都会发生变化,从而分散感知系统的注意力。其他透明或半透明物体包括胶带以及调味品杯的杯盖和杯身,这使得它们很难被精确感知,也不适合深度摄像头。黑色桌面也会与许多感兴趣的物体形成低对比度,例如黑色魔术贴电缆扎带和黑胶带分配器。特别是从俯视图来看,由于投影面积较小,要确定魔术贴绑带的位置非常困难。
5.2 数据采集
作者利用 ALOHA 机器人遥操作收集了所有 6 个真实世界任务的演示过程。根据任务的复杂程度,人类操作员执行每项任务的时间为 8-14 秒,如果控制频率为 50Hz,则需要 400-700 个时间步骤。作者为每项任务录制了 50 次演示,只有 “系上魔术贴 “任务录制了 100 次。因此,每项任务的演示数据总量约为 10-20 分钟,由于重置和遥控操作员的失误,时间约为 30-60 分钟。对于两个模拟任务,作者收集了两种类型的演示:一种是固定程序的策略类型,另一种是人工演示类型。在模拟远程操作中,作者使用 ALOHA 的 “领导机器人 “来控制模拟机器人,操作员则在监视器上观看环境的实时渲染。在这两种情况下,作者都记录了 50 次成功的演示。
需要强调的是,所有的人类演示过程本身都是随机的,即使所有的演示都是由一个人收集的。以磁带片段的空中交接为例:每次交接的确切位置都不同。人类没有视觉或触觉上的参考,无法在相同的位置上完成交接。因此,为了成功完成任务,策略需要学习两个抓手在交接过程中绝不能相互碰撞,而且左侧抓手应始终移动到能抓住磁带的位置,而不是试图记住交接的确切位置,因为不同的演示可能会有不同的交接位置。
5.3 实验结果
作者将 ��� 与之前的四种模仿学习方法进行了比较。
��−������� 是最简单但应用最广泛的baseline,它通过卷积网络处理当前图像观察结果,其输出特性与联合位置相串联,从而预测动作。
��� 也采用Transformer作为架构,但有一些主要区别:(1) 没有动作分块:模型根据历史观察结果只预测一个动作;(2) 图像观察结果由单独训练的视觉Encoder进行预处理。也就是说,感知和控制网络没有联合优化。
��−1 是另一种基于Transformer的架构,它能从固定长度的过去观察历史中预测一个动作。
��� 和 ��−1 都对动作空间进行了离散化处理:输出结果是离散分区上的分类分布,但在 ��� 的情况下,会从分区中心增加一个连续偏移量。而作者的方法 ACT 为了提高精细操作所需要的精度,直接预测连续动作。
最后, ���� 是一种非参数方法,它假定在测试时可以访问演示过程。给定一个新的观察结果,它会检索视觉特征最相似的 k 个观察结果,并利用加权 k 近邻法返回一个动作。视觉特征提取器是通过无监督学习对演示数据进行微调的预训练 ResNet。作者使用立方转移法仔细调整了这四种先验方法的超参数。超参数详情见附录 D。
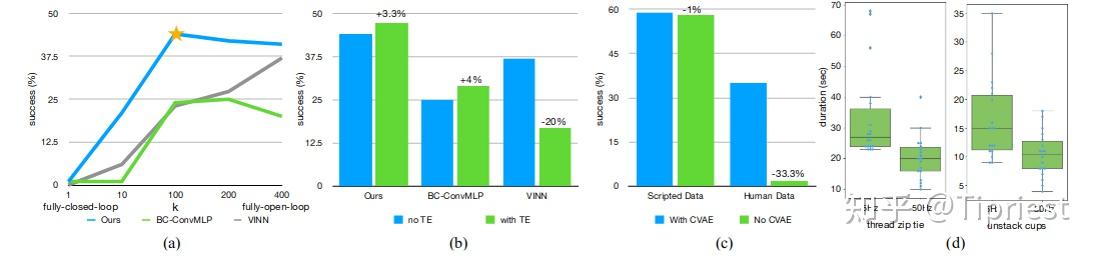
作为与先前方法的详细比较,作者在下表中报告了两个模拟任务和两个真实任务的平均成功率。对于模拟任务,作者采用 3 个随机种子,每个种子 50 次试验的平均成绩。作者报告了脚本数据(分隔条左侧)和人类数据(分隔条右侧)的成功率。对于真实世界的任务,作者运行一个种子,用 25 次试验进行评估。与之前的所有方法相比,ACT 获得了最高的成功率,在每个任务上都远远超过了排名第二的算法。在两个使用脚本或人类数据的模拟任务中,ACT 的成功率分别比之前最好的方法高出 59%、49%、29% 和 20%。虽然以前的方法能在前两个子任务中取得进展,但最终成功率仍然很低,低于 30%。对于打开拉链和插入电池这两个真实世界的任务,ACT 的最终成功率分别达到了 88% 和 96%,而其他方法在第一阶段之后就毫无进展了。作者将先前方法的不佳表现归因于数据中的复合误差和非马尔可夫行为:机器人的行为在一个episode结束时会明显退化,而且机器人会在某些状态下永远暂停。ACT 通过动作分块技术缓解了这两个问题。作者在第 VI-A 小节中进行的消融试验也表明,如果采用分块法,可以显著改善这些先前的方法。此外,在模拟任务中,当从脚本数据转换到人类数据时,我们注意到所有方法的性能都有所下降:人类演示的随机性和多模态性使得模仿学习变得更加困难。

作者在表 II 中报告了其余 3 个真实世界任务的成功率。在这些任务中,作者只与 ��� 进行了比较,后者是迄今为止任务成功率最高的。作者的 ACT 方法在 “打开调料罐 “任务中的成功率为 84%,在 “系上魔术贴 “任务中的成功率为 20%,在 “准备胶带 “任务中的成功率为 64%,在 “穿鞋 “任务中的成功率为 92%。我们观察到,ACT 在 “系上魔术贴 “中的成功率相对较低,从第一阶段的 92% 到最后的 20%,每个阶段的成功率都下降了一半左右。我们观察到的失败模式有:1)在第二阶段,右臂过早关闭抓手,未能在半空中抓住扎线带的尾部;2)在第三阶段,插入不够精确,错过了线圈。在这两种情况下,都很难通过图像观察来确定扎线带的确切位置:黑色扎线带与背景之间的对比度很低,而且扎线带只占图像的一小部分。作者在附录 B 中提供了图像观测的示例。
六. 消融实验
ACT 采用了动作分块和时间集成技术,以减少复合误差并更好地处理人类延时过程中非马尔可夫式的步骤。此外,它还将策略训练为条件 VAE来建模不稳定的人类演示过程。在本节中,我们将逐一去除这些组件,并通过实验强调 ALOHA 中高频控制的必要性。作者总共报告了四种情况下的结果:两种带有脚本或人工演示的模拟任务。





评论0