
来源:https://zhuanlan.zhihu.com/p/16403276747
FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
任务:
机械臂抓取物体,并通过多步骤调整到合适位姿,再去进行放置。

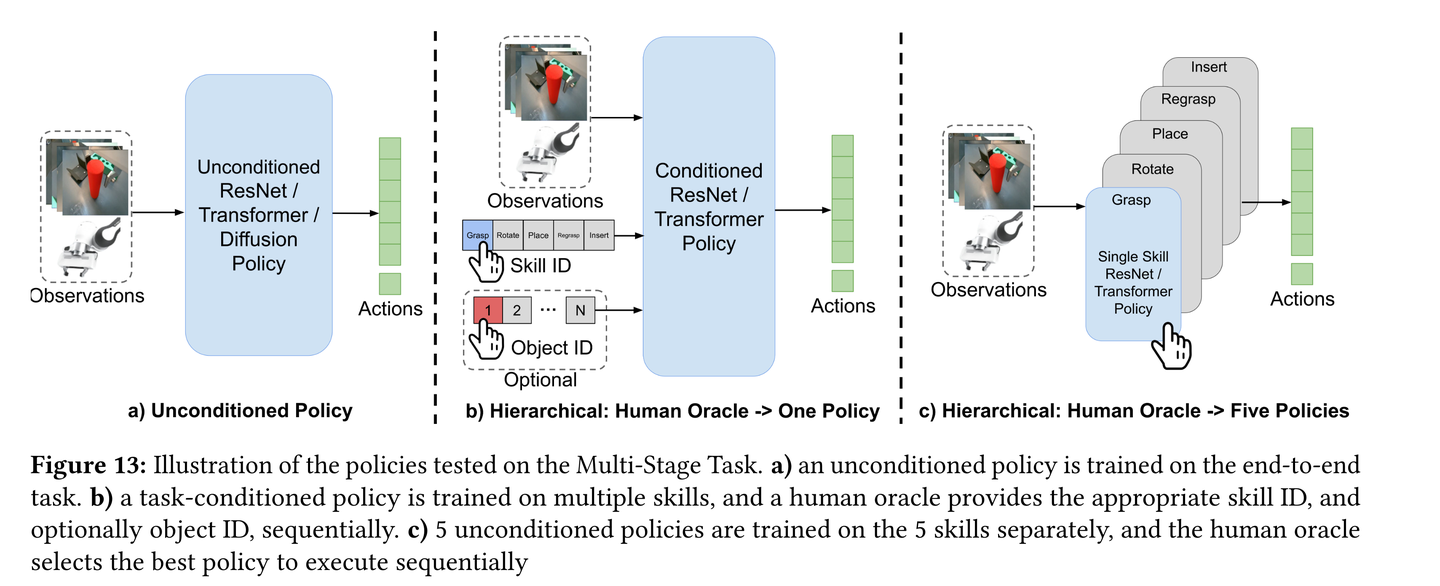
图13展示了在FMB(Functional Manipulation Benchmark)的多阶段操纵任务中,不同策略的测试情况。具体来说,图13展示了三种不同方法来处理这些任务:
(a) 无条件策略(Unconditioned Policy)
- 描述:这种策略是直接在完整的长时序演示数据上训练的“扁平”(flat)端到端模仿学习策略。它没有进行任何条件化处理,试图一次性学习整个任务序列.
- 应用场景:适用于简单的任务,但在复杂的多阶段任务中表现不佳,因为容易受到各个阶段引入的累积误差的影响.
(b) 任务条件化策略(Task-Conditioned Policy)
- 描述:这种策略通过训练一个单一的策略来处理多个技能,但通过人类提供的技能ID(以及可选的物体ID)进行条件化处理。在执行过程中,人类“预言者”(oracle)会根据当前的任务状态,顺序地提供适当的技能ID和物体ID,以触发相应的低级技能.
- 应用场景:适用于需要在不同任务阶段之间进行灵活切换的情况,能够通过条件化机制来减少累积误差,并更好地适应复杂的任务结构.
(c) 多策略组合(Five Policies)
- 描述:在这种方法中,训练五个独立的策略,每个策略代表一个特定的低级技能。在执行过程中,人类预言者会根据任务的需要,顺序地选择并执行相应的策略.
- 应用场景:适用于需要精确控制每个单独技能的情况,通过将任务分解为多个独立的技能模块,可以更好地处理复杂的任务序列,并提高整体任务的成功率.
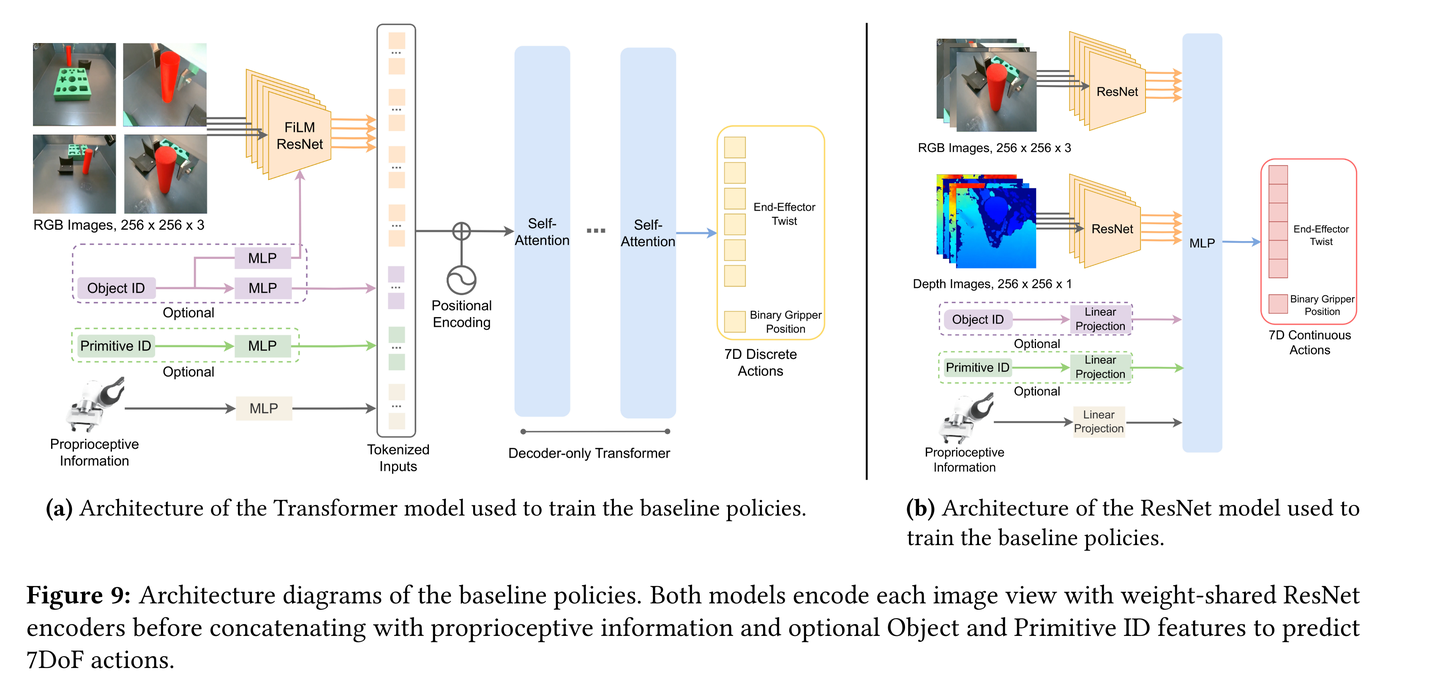
baseline网络架构:
(a) Transformer模型架构
- 输入处理:使用共享权重的ResNet-34编码器对来自多个摄像机视图的图像进行编码。如果需要,还会添加FiLM(Feature-wise Linear Modulation)层来根据物体ID或操作技能ID进行条件化处理。这有助于确保网络能够根据输入的ID向量正确地调整其行为.
- 机器人本体感知信息:通过一个单独的MLP(多层感知机)对机器人的本体感知信息(如末端执行器的姿态、速度或力/扭矩测量)进行编码.
- 自注意力机制:将编码后的图像特征、本体感知信息以及位置嵌入(sinusoidal position embeddings)拼接在一起,然后通过自注意力层进行处理。自注意力层包含四个注意力头和四个MLP层.
- 输出:网络输出一个离散化的动作,包括一个6D末端执行器的旋转和一个二进制变量,指示夹持器是打开还是关闭。在训练期间,每个连续的6D机器人动作空间维度被离散化为256个bin,使用高斯量化器进行处理.
(b) ResNet模型架构
- 输入处理:同样使用ResNet-34作为视觉骨干网络,对多个RGB和深度图像进行编码。这些图像特征在编码后被拼接在一起.
- 机器人本体感知信息:将机器人的本体感知信息(如末端执行器的姿态、速度或力/扭矩测量)进行线性投影,然后与图像特征一起输入到MLP中.
- 条件化处理:系统能够根据物体ID和操作技能ID进行条件化处理,这些ID被表示为独热向量(one-hot vectors).
- 输出:输出是一个6D末端执行器的旋转以及一个二进制变量,指示夹持器是打开还是关闭
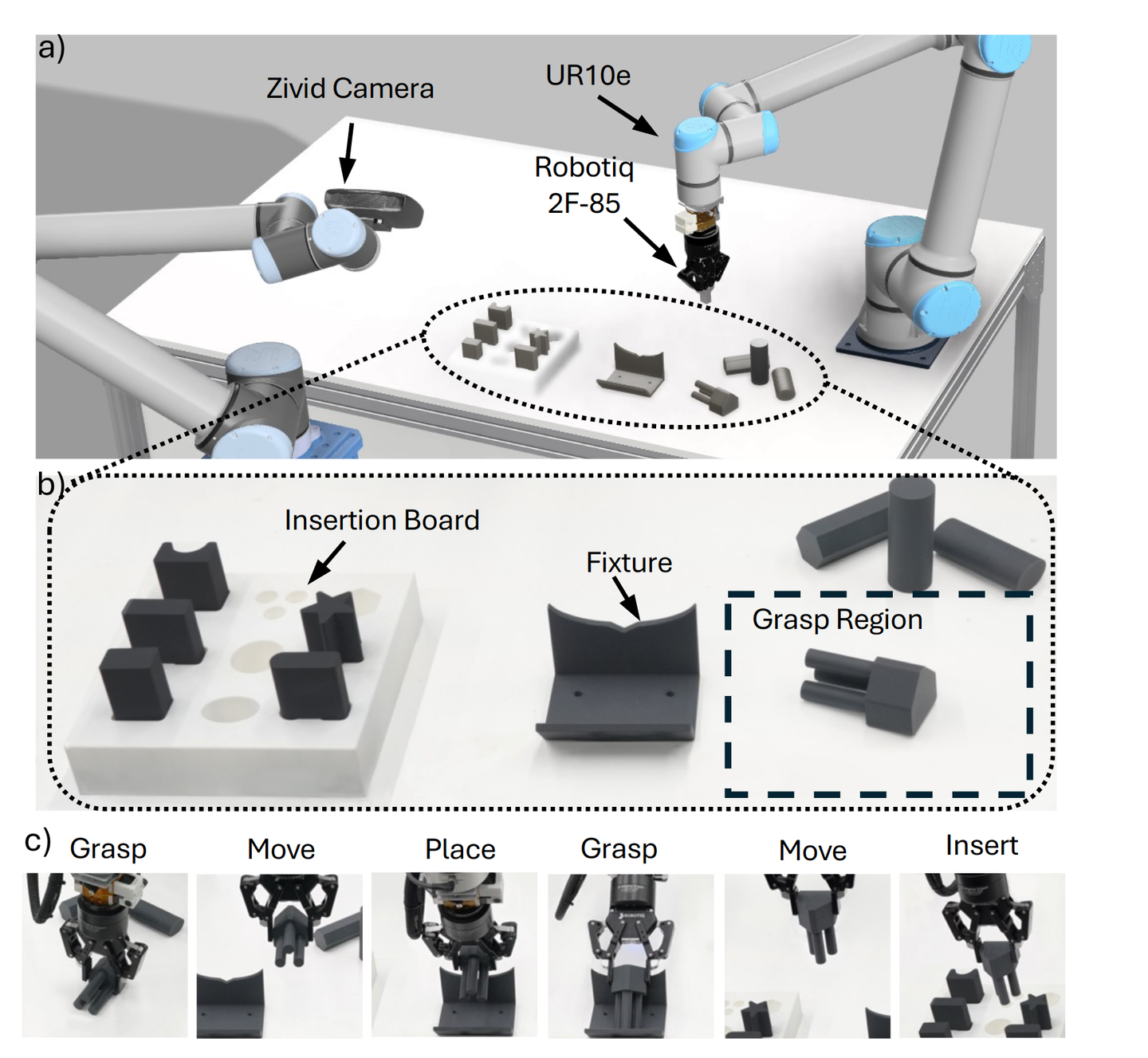
另一篇 Hierarchical Hybrid Learning for Long-Horizon Contact-Rich Robotic Assembly
这篇文章介绍了一种名为ARCH(Adaptive Robotic Compositional Hierarchy)的分层混合学习系统,用于处理长期、接触丰富的机器人装配任务。文章的核心目标是解决传统编程方法难以应对的复杂装配任务,这些任务需要机器人具备高精度和适应性。为此,作者提出了一种结合低层次技能库和高层次策略的分层框架。低层次技能库包括基本的装配技能,如抓取和插入,这些技能通过运动规划算法和强化学习(RL)策略实现。具体来说,运动规划算法用于指导机器人末端执行器到达目标位置,而RL策略则用于处理复杂的接触操作,如插入任务。这些RL策略在模拟环境中进行训练,并通过领域随机化实现从模拟到现实世界的零样本迁移。高层次策略则通过模仿学习从少量的人类演示中学习,选择和组合这些低层次技能以实现最终的装配目标。该框架的优势在于其数据效率高,能够在有限的演示数据下实现良好的泛化能力,同时满足装配任务的高精度要求。通过在真实机器人平台上进行广泛的实验,作者证明了ARCH在单一任务训练后能够很好地泛化到未见过的任务,并在成功率和数据效率方面优于基线方法。
在文章中提到的高级策略 πθ 是通过模仿学习获得的,其主要功能是从低层次技能库中选择最适合当前任务的技能,并为其提供连续的参数。具体来说,该策略接收来自姿态估计的物体姿态信息和机器人的本体感知信息作为输入,输出一个分类分布,用于选择最佳的低层次技能以及该技能的连续参数。通过模仿学习,该策略能够从少量的人类演示中学习如何在不同的任务环境中有效地选择和配置低层次技能,从而实现复杂的装配任务。这种方法的优势在于,它不需要大量的演示数据,能够快速适应新的任务场景,提高了系统的数据效率和泛化能力。
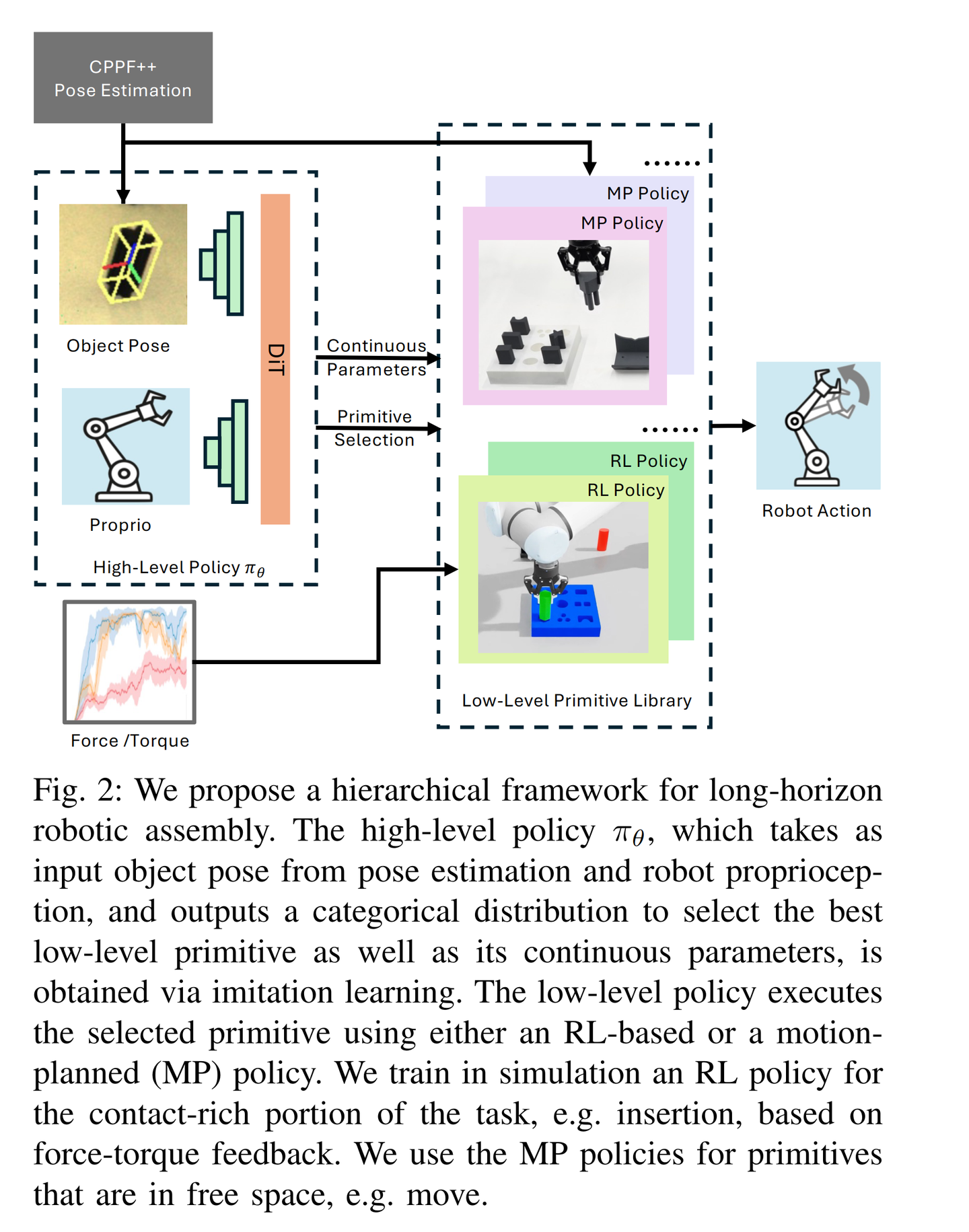
在文章中,高级策略 πθπθ 的模仿学习数据收集和训练过程如下:
数据收集
- 演示任务选择:首先,研究人员在训练好的低层次技能库的基础上,让人类专家通过键盘顺序选择不同的低层次技能来完成多阶段的装配任务。例如,在进行抓取任务时,演示者选择抓取技能的索引,然后将姿态估计模块获得的物体姿态传递给运动规划器以执行该技能。
- 数据集构成:收集到的数据集 D={(s,a,x)}D={(s,a,x)} 包含了传感器观测 ss、技能索引 aa 以及对应的连续技能参数 xx。数据集包括两种类型的演示:“成功”演示和“恢复”演示。在大约20次演示中,演示者成功地将物体插入目标位置;在剩余的20次演示中,演示者展示了在失败后如何进行恢复操作。这些“恢复”演示对于提高学习策略的鲁棒性至关重要,因为它们帮助策略学会如何从演示数据中未出现的意外情况中恢复过来。
- 数据增强:为了提高策略的鲁棒性,研究人员通过在机器人的状态中引入噪声来增强数据集。这意味着在收集的数据中,机器人的实际状态会有一些随机扰动,从而使得学习到的策略能够更好地适应实际操作中可能出现的各种变化。
训练过程
- 模型架构:高级策略 πθπθ 采用修改后的Diffusion Transformer(DiT)架构作为其骨干网络。DiT架构具有强大的序列数据处理能力,适合处理之前状态和动作的历史信息。DiT输出每个低层次技能的softmax分数以及具有最高分数技能的连续动作参数。
- 损失函数:在训练过程中,使用交叉熵损失来监督对每个低层次技能的softmax分数的预测,使用均方误差(MSE)损失来监督对具有最高分数技能的连续动作参数的预测。通过最小化这些损失函数,模型能够学习如何根据输入的状态信息准确地选择和配置低层次技能。
- 优化目标:模仿学习的目标是找到一个参数化的策略 πθπθ,使得根据当前收集到的演示数据 D={(s,a,x)}D={(s,a,x)} 的似然函数最大化。即通过调整模型参数 θθ,使得模型输出的技能选择和参数配置尽可能接近人类专家在演示中所做出的决策。

高级策略 πθ 的输出包括两个主要部分:连续参数(continuous parameters)和技能选择(primitive selection)。
连续参数(Continuous Parameters)
- 定义:连续参数是指用于具体执行低层次技能时的详细控制参数。这些参数通常是连续的数值,可以用来调整技能的具体执行方式。例如,在抓取技能中,连续参数可能包括机器人末端执行器的目标位置、姿态或者抓取力度等。
- 作用:通过输出连续参数,高级策略能够精确地指导低层次技能的执行。这使得机器人能够根据当前的任务需求和环境条件灵活地调整技能的执行细节,从而提高任务的成功率和适应性。
技能选择(Primitive Selection)
- 定义:技能选择是指从低层次技能库中选择最适合当前任务需求的技能。低层次技能库中包含了多种基本的装配技能,如抓取、放置、移动和插入等。
- 作用:高级策略通过输出一个分类分布来实现技能选择。这个分类分布为每个低层次技能分配一个概率值,表示在当前状态下选择该技能的可能性。策略会根据这个分布选择概率最高的技能来执行。通过合理的技能选择,机器人能够有效地组合和利用各种基本技能来完成复杂的装配任务。
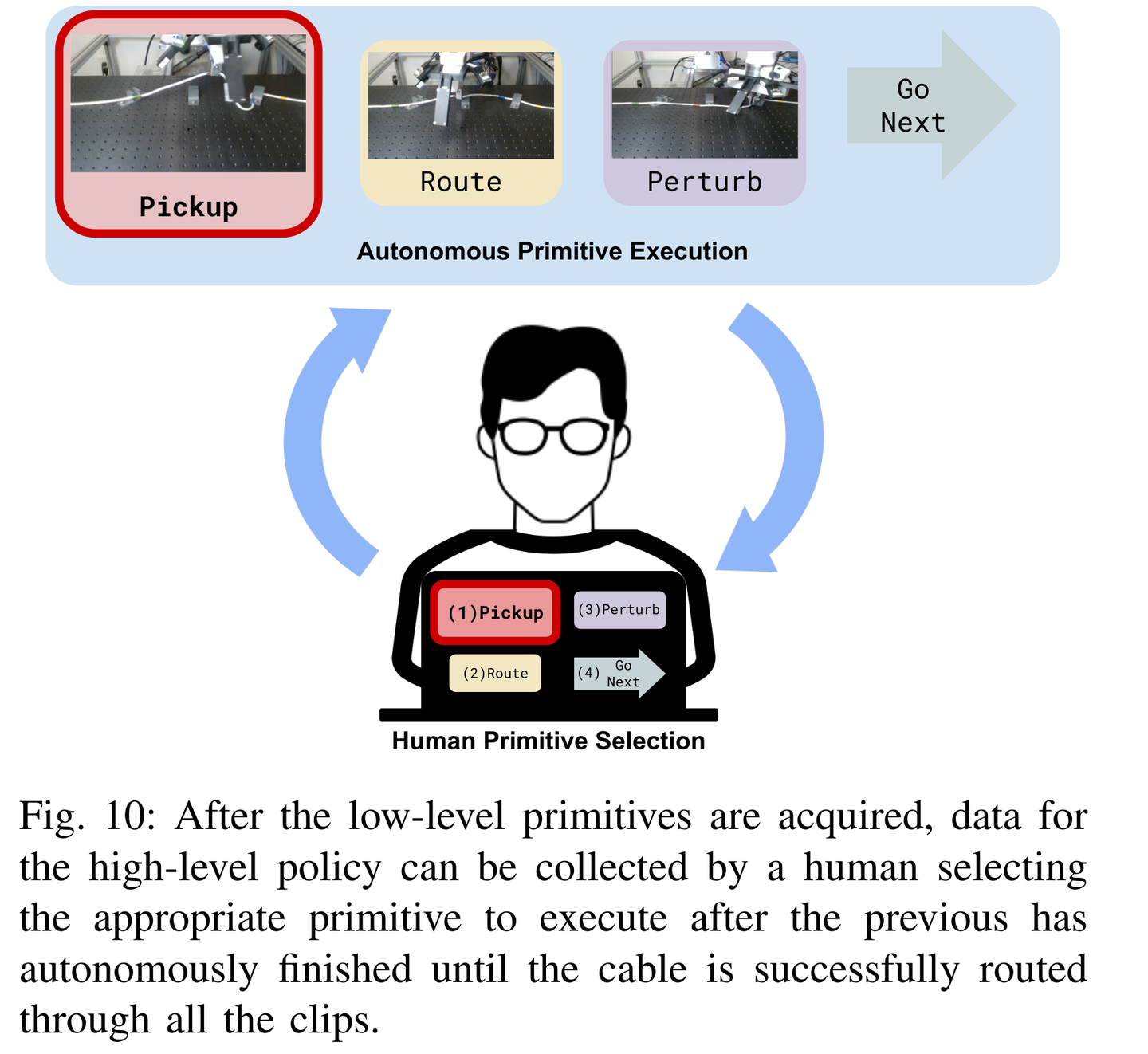
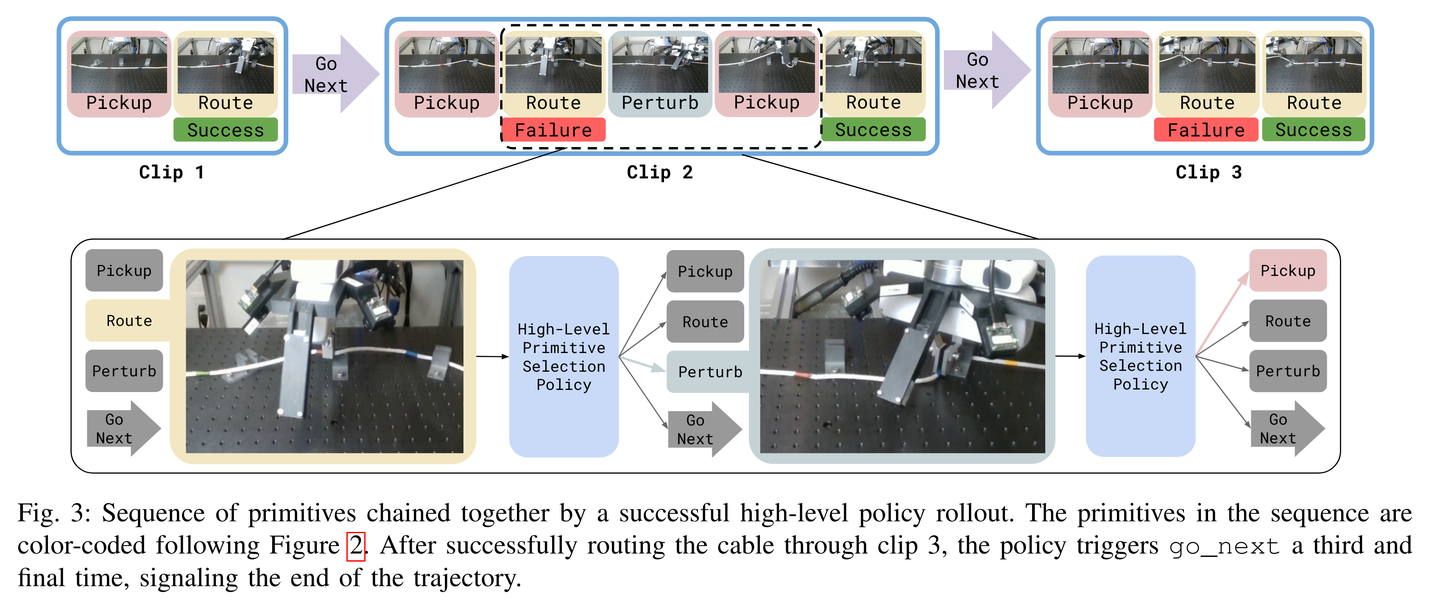
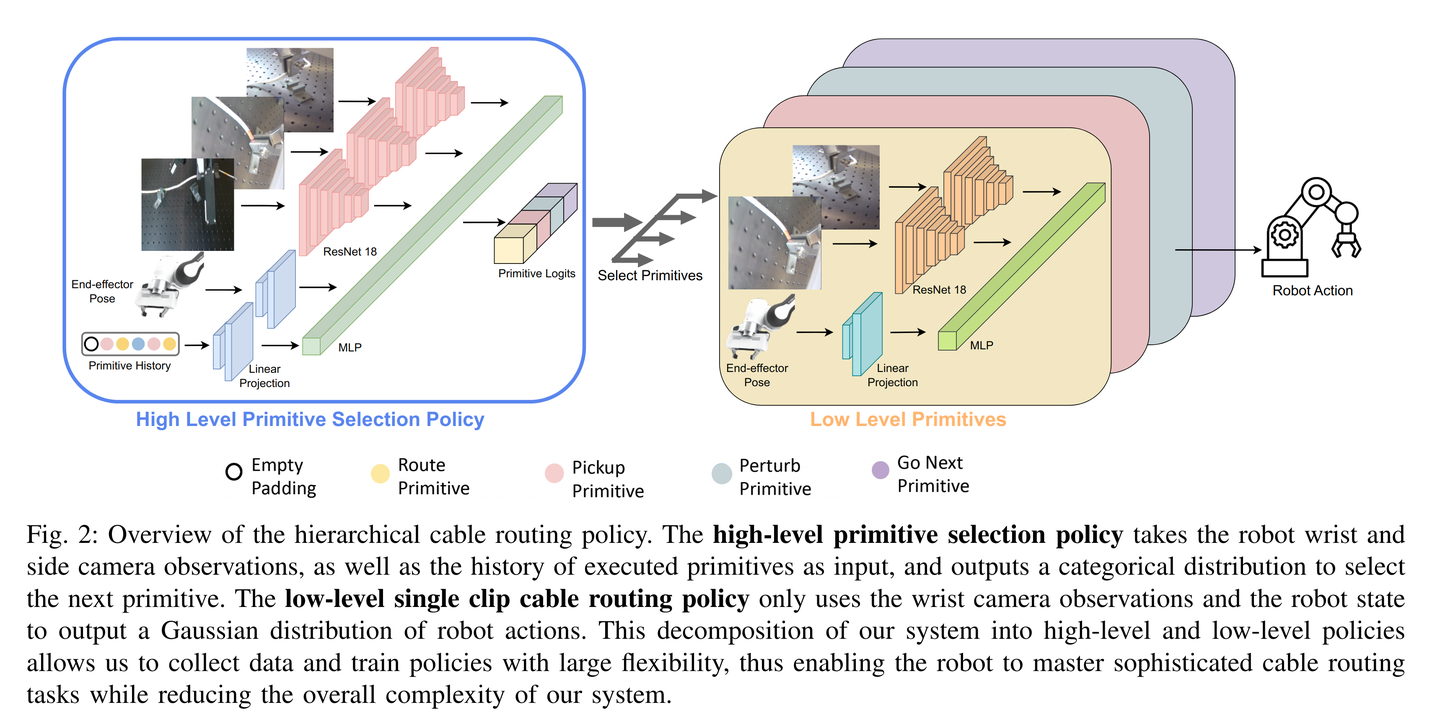
第二篇的灵感来源于下面这篇文章:Multi-Stage Cable Routing Through Hierarchical Imitation Learning
但任务不一样,网络架构也不一样





评论0