
来源:https://zhuanlan.zhihu.com/p/1965926217799668558
视频讲解:
仓库代码:
GitHub – LitchiCheng/mujoco-learninggithub.com/LitchiCheng/mujoco-learning
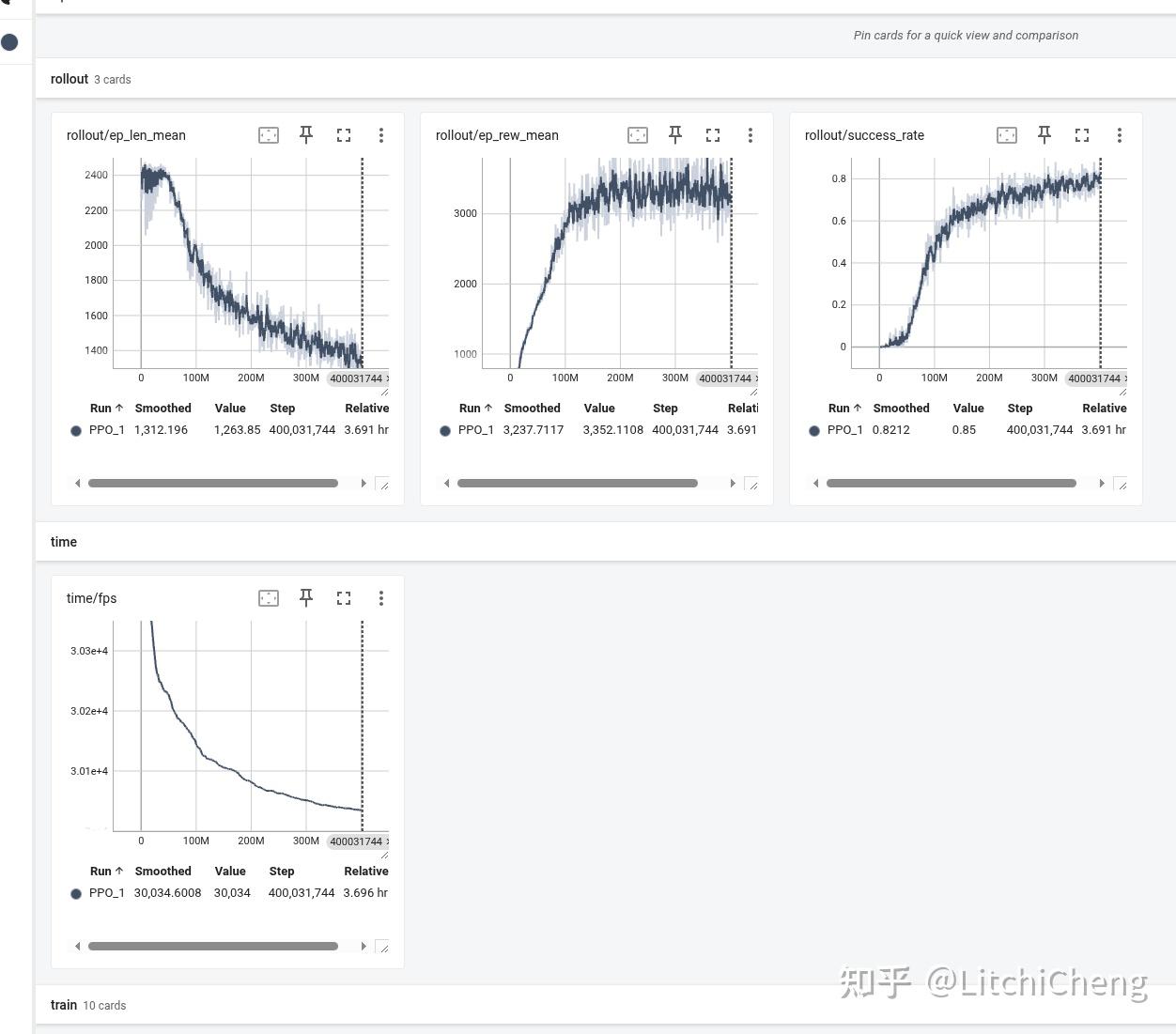
前面做过一期《MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)》,但是没有包含路径规划,在此基础上可以增加难度,让强化学习来帮我们找到一条路径(当然不一定是最优的,条条大路通罗马,要想寻好一条时间、空间都最优的模型,需要不停的微调奖励函数),下面看下4ww次训练后的成功率基本上达到80%,但实际测试下来可以看到路径规划会比较傻,而且到点后会有震荡,这些都是要进一步优化的内容。
PPO 的策略网络和价值网络都使用两层,激活函数选择 ReLU
# 策略网络配置
POLICY_KWARGS = dict(
activation_fn=nn.ReLU,
net_arch=[dict(pi=[256, 128], vf=[256, 128])]
)
# PPO模型
model = PPO(
policy="MlpPolicy",
env=env,
policy_kwargs=POLICY_KWARGS,
verbose=1,
n_steps=2048,
batch_size=2048,
n_epochs=10,
gamma=0.99,
learning_rate=3e-4,
device="cuda" if torch.cuda.is_available() else "cpu",
tensorboard_log="./tensorboard/panda_reach_target/"
)使用PPO进行强化学习,同时利用前面介绍过的tensorboard可视化训练过程,调整env可以并行训练,实际还是比较快的,主要这个维度不是很大
def _calc_reward(self, ee_pos: np.ndarray, ee_orient: np.ndarray, joint_angles: np.ndarray, action: np.ndarray) -> tuple[np.ndarray, float]:
dist_to_goal = np.linalg.norm(ee_pos - self.goal)
# 非线性距离奖励
if dist_to_goal < self.goal_threshold:
distance_reward = 100.0
elif dist_to_goal < 2*self.goal_threshold:
distance_reward = 50.0
elif dist_to_goal < 3*self.goal_threshold:
distance_reward = 10.0
else:
distance_reward = 1.0 / (1.0 + dist_to_goal)
# 姿态约束:保持末端朝下
target_orient = np.array([0, 0, -1])
ee_orient_norm = ee_orient / np.linalg.norm(ee_orient)
dot_product = np.dot(ee_orient_norm, target_orient)
angle_error = np.arccos(np.clip(dot_product, -1.0, 1.0))
orientation_penalty = 0.3 * angle_error
# 动作相关惩罚
action_diff = action - self.prev_action
smooth_penalty = 0.1 * np.linalg.norm(action_diff)
action_magnitude_penalty = 0.05 * np.linalg.norm(action)
contact_reward = 1.0*self.data.ncon
# 关节角度限制惩罚
joint_penalty = 0.0
for i in range(7):
min_angle, max_angle = self.model.jnt_range[:7][i]
if joint_angles[i] < min_angle:
joint_penalty += 0.5 * (min_angle - joint_angles[i])
elif joint_angles[i] > max_angle:
joint_penalty += 0.5 * (joint_angles[i] - max_angle)
# 时间惩罚
time_penalty = 0.01
# 总奖励计算
# total_reward = distance_reward - contact_reward - smooth_penalty - action_magnitude_penalty - joint_penalty - time_penalty - orientation_penalty
total_reward = distance_reward - contact_reward - smooth_penalty - orientation_penalty # - joint_penalty # - orientation_penalty
# print(f"[奖励] 距离目标: {distance_reward:.3f}, [碰撞]: {contact_reward:.3f}, 动作惩罚: {smooth_penalty:.3f}, 姿态: {orientation_penalty:.3f} 总奖励: {total_reward:.3f}")
# 更新上一步动作
self.prev_action = action.copy()
return total_reward, dist_to_goal, angle_error强化学习比较重要的就是奖励函数的设计,按照经验来说,刚开始可以单个环境调整奖励函数来观察是不是前期奖励太稀疏,无法学到规律,通过打印reward观察,也不要一次性上难度,各种约束都加上的话,基本上很难成功,不成功对于规律来说就很难找到,自然无法成功训练,如下是完整代码
import numpy as np
import mujoco
import gym
from gym import spaces
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.vec_env import SubprocVecEnv, DummyVecEnv
import torch.nn as nn
import warnings
import torch
import mujoco.viewer
import random
import time
from typing import Optional
from scipy.spatial.transform import Rotation as R
# 忽略stable-baselines3的冗余UserWarning
warnings.filterwarnings("ignore", category=UserWarning, module="stable_baselines3.common.on_policy_algorithm")
class PandaObstacleEnv(gym.Env):
def __init__(self, visualize: bool = False):
super(PandaObstacleEnv, self).__init__()
self.visualize = visualize
self.handle = None
self.model = mujoco.MjModel.from_xml_path('./model/franka_emika_panda/scene.xml')
self.data = mujoco.MjData(self.model)
if self.visualize:
self.handle = mujoco.viewer.launch_passive(self.model, self.data)
self.handle.cam.distance = 3.0
self.handle.cam.azimuth = 0.0
self.handle.cam.elevation = -30.0
self.handle.cam.lookat = np.array([0.2, 0.0, 0.4])
self.end_effector_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, 'ee_center_body')
self.initial_ee_pos = np.zeros(3, dtype=np.float32)
self.home_joint_pos = np.array([ # home位姿
0.0, -np.pi/4, 0.0, -3*np.pi/4,
0.0, np.pi/2, np.pi/4
], dtype=np.float32)
self.goal_size = 0.03
# 约束工作空间
self.workspace = {
'x': [-0.5, 0.8],
'y': [-0.5, 0.5],
'z': [0.05, 0.3]
}
# 动作空间与观测空间
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(7,), dtype=np.float32)
# 7轴关节角度、目标位置
self.obs_size = 7 + 3
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.obs_size,), dtype=np.float32)
self.goal = np.zeros(3, dtype=np.float32)
self.np_random = np.random.default_rng(None)
self.prev_action = np.zeros(7, dtype=np.float32)
self.goal_threshold = 0.005
def _get_valid_goal(self) -> np.ndarray:
"""生成有效目标点"""
while True:
goal = self.np_random.uniform(
low=[self.workspace['x'][0], self.workspace['y'][0], self.workspace['z'][0]],
high=[self.workspace['x'][1], self.workspace['y'][1], self.workspace['z'][1]]
)
if 0.4 < np.linalg.norm(goal - self.initial_ee_pos) < 0.5 and goal[0] > 0.2 and goal[2] > 0.2:
return goal.astype(np.float32)
def _render_scene(self) -> None:
"""渲染目标点"""
if not self.visualize or self.handle is None:
return
self.handle.user_scn.ngeom = 0
total_geoms = 1
self.handle.user_scn.ngeom = total_geoms
# 渲染目标点(蓝色)
goal_rgba = np.array([0.1, 0.1, 0.9, 0.9], dtype=np.float32)
mujoco.mjv_initGeom(
self.handle.user_scn.geoms[0],
mujoco.mjtGeom.mjGEOM_SPHERE,
size=[self.goal_size, 0.0, 0.0],
pos=self.goal,
mat=np.eye(3).flatten(),
rgba=goal_rgba
)
def reset(self, seed: Optional[int] = None, options: Optional[dict] = None) -> tuple[np.ndarray, dict]:
super().reset(seed=seed)
if seed is not None:
self.np_random = np.random.default_rng(seed)
# 重置关节到home位姿
mujoco.mj_resetData(self.model, self.data)
self.data.qpos[:7] = self.home_joint_pos
mujoco.mj_forward(self.model, self.data)
self.initial_ee_pos = self.data.body(self.end_effector_id).xpos.copy()
# 生成目标和障碍物
self.goal = self._get_valid_goal()
if self.visualize:
self._render_scene()
obs = self._get_observation()
self.start_t = time.time()
return obs, {}
def _get_observation(self) -> np.ndarray:
joint_pos = self.data.qpos[:7].copy().astype(np.float32)
# ee_pos = self.data.body(self.end_effector_id).xpos.copy().astype(np.float32)
# ee_quat = self.data.body(self.end_effector_id).xquat.copy().astype(np.float32)
return np.concatenate([joint_pos, self.goal])
def _calc_reward(self, ee_pos: np.ndarray, ee_orient: np.ndarray, joint_angles: np.ndarray, action: np.ndarray) -> tuple[np.ndarray, float]:
dist_to_goal = np.linalg.norm(ee_pos - self.goal)
# 非线性距离奖励
if dist_to_goal < self.goal_threshold:
distance_reward = 100.0
elif dist_to_goal < 2*self.goal_threshold:
distance_reward = 50.0
elif dist_to_goal < 3*self.goal_threshold:
distance_reward = 10.0
else:
distance_reward = 1.0 / (1.0 + dist_to_goal)
# 姿态约束:保持末端朝下
target_orient = np.array([0, 0, -1])
ee_orient_norm = ee_orient / np.linalg.norm(ee_orient)
dot_product = np.dot(ee_orient_norm, target_orient)
angle_error = np.arccos(np.clip(dot_product, -1.0, 1.0))
orientation_penalty = 0.3 * angle_error
# 动作相关惩罚
action_diff = action - self.prev_action
smooth_penalty = 0.1 * np.linalg.norm(action_diff)
action_magnitude_penalty = 0.05 * np.linalg.norm(action)
contact_reward = 1.0*self.data.ncon
# 关节角度限制惩罚
joint_penalty = 0.0
for i in range(7):
min_angle, max_angle = self.model.jnt_range[:7][i]
if joint_angles[i] < min_angle:
joint_penalty += 0.5 * (min_angle - joint_angles[i])
elif joint_angles[i] > max_angle:
joint_penalty += 0.5 * (joint_angles[i] - max_angle)
# 时间惩罚
time_penalty = 0.01
# 总奖励计算
# total_reward = distance_reward - contact_reward - smooth_penalty - action_magnitude_penalty - joint_penalty - time_penalty - orientation_penalty
total_reward = distance_reward - contact_reward - smooth_penalty - orientation_penalty # - joint_penalty # - orientation_penalty
# print(f"[奖励] 距离目标: {distance_reward:.3f}, [碰撞]: {contact_reward:.3f}, 动作惩罚: {smooth_penalty:.3f}, 姿态: {orientation_penalty:.3f} 总奖励: {total_reward:.3f}")
# 更新上一步动作
self.prev_action = action.copy()
return total_reward, dist_to_goal, angle_error
def step(self, action: np.ndarray) -> tuple[np.ndarray, np.float32, bool, bool, dict]:
# 动作缩放
joint_ranges = self.model.jnt_range[:7]
scaled_action = np.zeros(7, dtype=np.float32)
for i in range(7):
scaled_action[i] = joint_ranges[i][0] + (action[i] + 1) * 0.5 * (joint_ranges[i][1] - joint_ranges[i][0])
# 执行动作
self.data.qpos[:7] = scaled_action
mujoco.mj_step(self.model, self.data)
# 计算奖励与状态
ee_pos = self.data.body(self.end_effector_id).xpos.copy()
ee_quat = self.data.body(self.end_effector_id).xquat.copy()
rot = R.from_quat(ee_quat)
ee_quat_euler_rad = rot.as_euler('xyz')
reward, dist_to_goal,_ = self._calc_reward(ee_pos, ee_quat_euler_rad, self.data.qpos[:7], action)
terminated = False
collision = False
# 目标达成
if dist_to_goal < self.goal_threshold:
terminated = True
# print(f"[奖励] 距离目标: {dist_to_goal:.3f}, 奖励: {reward:.3f}")
if not terminated:
if time.time() - self.start_t > 20.0:
reward -= 10.0
print(f"[超时] 时间过长,奖励减半")
terminated = True
if self.visualize and self.handle is not None:
self.handle.sync()
time.sleep(0.01)
obs = self._get_observation()
info = {
'is_success': terminated and (dist_to_goal < self.goal_threshold),
'distance_to_goal': dist_to_goal,
'collision': collision
}
return obs, reward.astype(np.float32), terminated, False, info
def seed(self, seed: Optional[int] = None) -> list[Optional[int]]:
self.np_random = np.random.default_rng(seed)
return [seed]
def close(self) -> None:
if self.visualize and self.handle is not None:
self.handle.close()
self.handle = None
print("环境已关闭,资源释放完成")
def train_ppo(
n_envs: int = 24,
total_timesteps: int = 40_000_000,
model_save_path: str = "panda_ppo_reach_target",
visualize: bool = False
) -> None:
ENV_KWARGS = {'visualize': visualize}
# 创建多进程向量环境
env = make_vec_env(
env_id=lambda: PandaObstacleEnv(**ENV_KWARGS),
n_envs=n_envs,
seed=42,
vec_env_cls=SubprocVecEnv,
vec_env_kwargs={"start_method": "fork"}
)
# 策略网络配置
POLICY_KWARGS = dict(
activation_fn=nn.ReLU,
net_arch=[dict(pi=[256, 128], vf=[256, 128])]
)
# PPO模型
model = PPO(
policy="MlpPolicy",
env=env,
policy_kwargs=POLICY_KWARGS,
verbose=1,
n_steps=2048,
batch_size=2048,
n_epochs=10,
gamma=0.99,
learning_rate=3e-4,
device="cuda" if torch.cuda.is_available() else "cpu",
tensorboard_log="./tensorboard/panda_reach_target/"
)
print(f"并行环境数: {n_envs}, 总步数: {total_timesteps}")
model.learn(
total_timesteps=total_timesteps,
progress_bar=True
)
model.save(model_save_path)
env.close()
print(f"模型已保存至: {model_save_path}")
def test_ppo(
model_path: str = "panda_ppo_reach_target",
total_episodes: int = 5,
) -> None:
env = PandaObstacleEnv(visualize=True)
model = PPO.load(model_path, env=env)
record_gif = False
frames = [] if record_gif else None
render_scene = None
render_context = None
pixel_buffer = None
viewport = None
success_count = 0
print(f"测试轮数: {total_episodes}")
for ep in range(total_episodes):
obs, _ = env.reset()
done = False
episode_reward = 0.0
while not done:
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
episode_reward += reward
done = terminated or truncated
if info['is_success']:
success_count += 1
print(f"轮次 {ep+1:2d} | 总奖励: {episode_reward:6.2f} | 结果: {'成功' if info['is_success'] else '碰撞/失败'}")
success_rate = (success_count / total_episodes) * 100
print(f"总成功率: {success_rate:.1f}%")
env.close()
if __name__ == "__main__":
TRAIN_MODE = False
MODEL_PATH = "panda_ppo_reach_target"
if TRAIN_MODE:
train_ppo(
n_envs=256,
total_timesteps=400_000_000,
model_save_path=MODEL_PATH,
visualize = False
)
else:
test_ppo(
model_path=MODEL_PATH,
total_episodes=15,
)如果大家要重新训练的话,可以TRAIN_MODE改成True即可,只是测试的话,仓库中的 panda_ppo_reach_target.zip 就是目前训练好的模型(但这个肯定要继续优化训练,这里只是一个demo)
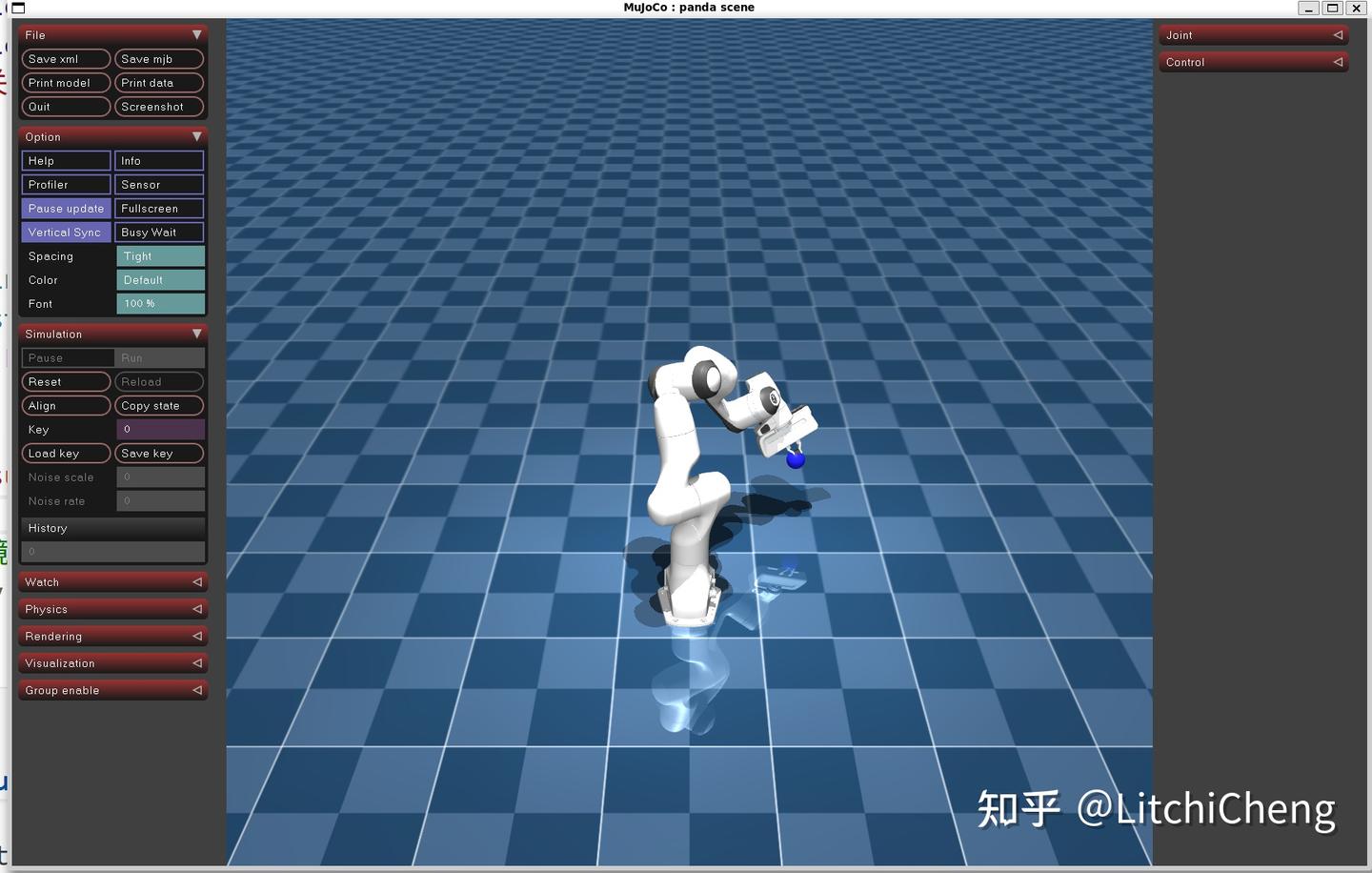
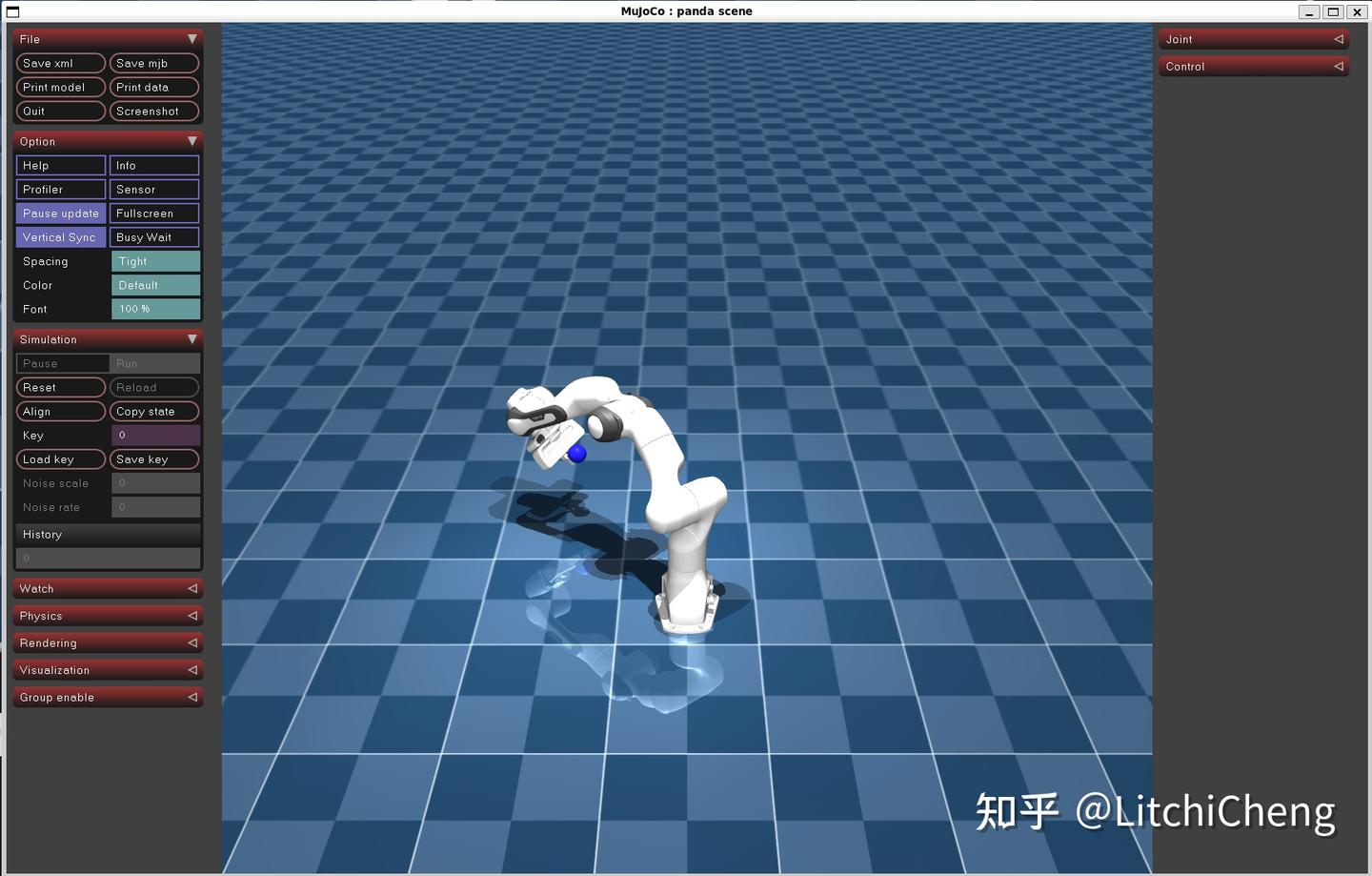
模型如下






评论0